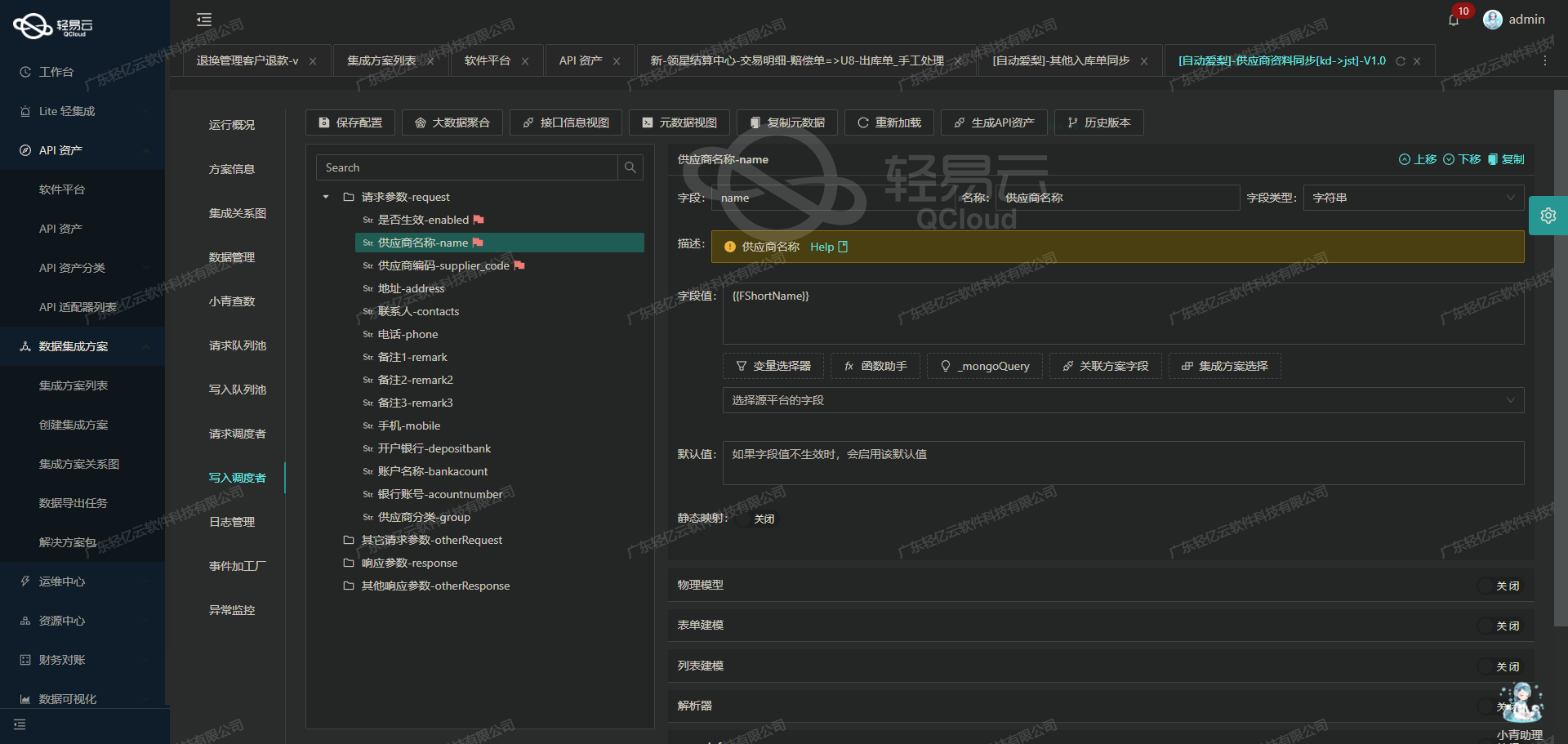
班牛数据集成案例分享:查询班牛供应商名称
为了满足企业在日常业务运作中对供应商信息的快速获取需求,本文将详细介绍如何通过轻易云数据集成平台实现班牛系统之间的数据对接。具体来说,我们将探讨以下几个关键步骤和技术要点:
-
调用班牛接口column.list:首先需要使用这个API从班牛数据库中获取到所有列的信息,以便后续的数据操作过程中能够准确地定位到所需的字段。
-
处理分页和限流问题:由于班牛接口存在分页和请求频率限制,在实际应用中必须设计高效的分页处理策略及限流控制机制,以确保数据抓取任务能顺利完成而不被阻断。
-
自定义数据转换逻辑:为了适应特定业务需求和数据结构,从源头抓取到的供应商名需要经过某些前置逻辑处理,比如字符串清洗或格式调整,这一步至关重要。
-
批量写入到目标系统:利用workflow.task.create API,将最终整理好的供应商名批量写入到班牛目标数据库。此过程中对大体量数据进行高效并行化处理,提高整体性能。
-
实时监控与告警系统:整个流程通过集中的监控和平面化管理界面,可视化追踪每个节点的状态,同时配置了智能告警功能,可以及时发现并解决潜在的问题。
-
异常检测与错误重试机制:为确保整个集成过程无误,引入了自动检测异常以及多次重试策略,一旦发生意外情况可以即时响应修正,保障任务顺利执行且不会遗漏关键数据。
以上内容将围绕"查询班牛供应商名称"这一具体应用场景展开详解,从初始化过程开始,到最终结果输出,让您全面掌握如何有效、精准、高效地进行跨系统的数据整合。在下文中,我们会进一步深入探讨每一环节所涉及的实用技巧与最佳实践方案。
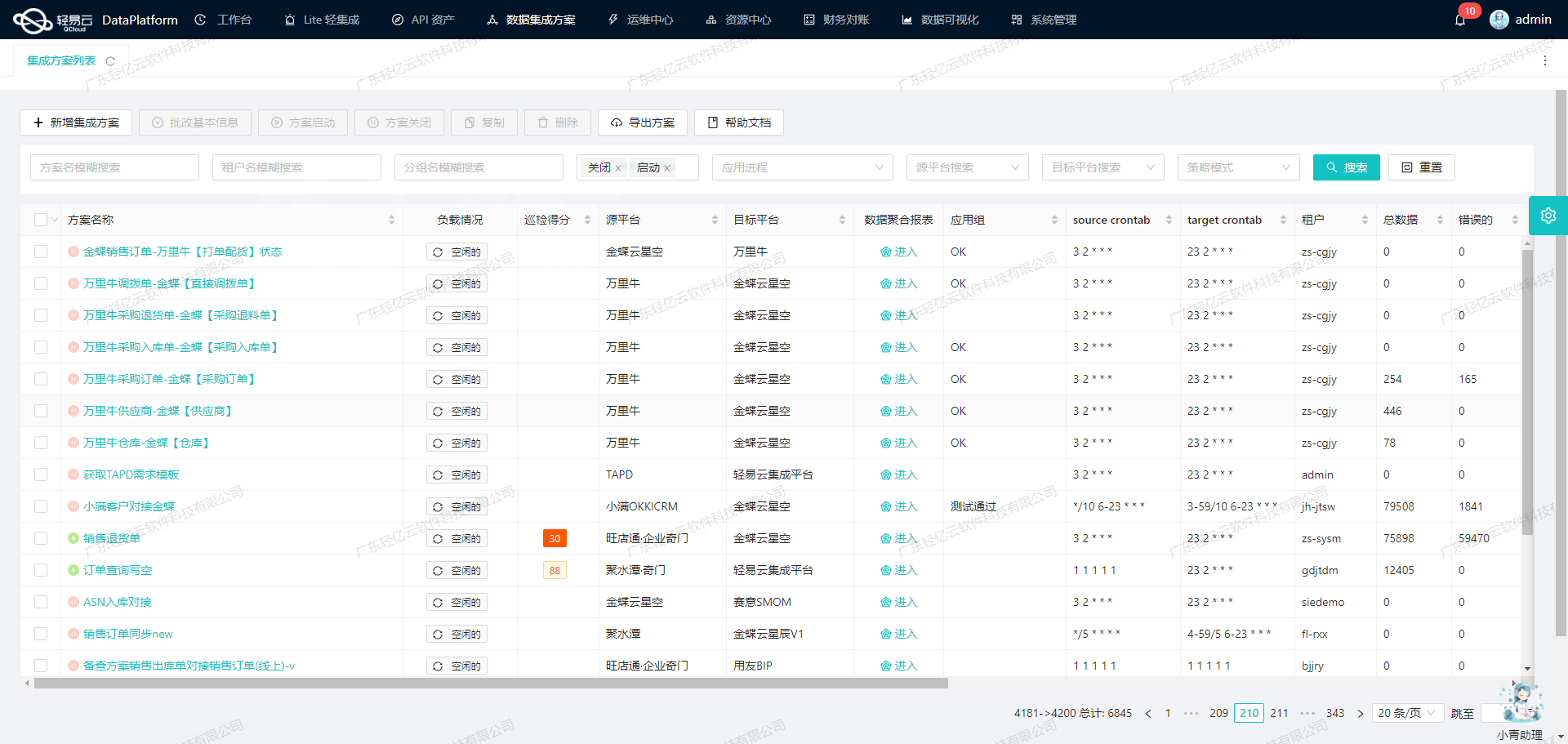
调用班牛接口column.list获取并加工数据
在数据集成过程中,调用源系统接口是至关重要的一步。本文将深入探讨如何通过轻易云数据集成平台调用班牛的column.list接口来获取并加工数据。
接口调用配置
首先,我们需要配置元数据以便正确调用班牛的column.list接口。以下是具体的元数据配置:
{
"api": "column.list",
"effect": "QUERY",
"method": "GET",
"number": "column_id",
"id": "column_id",
"idCheck": true,
"request": [
{
"field": "project_id",
"label": "project_id",
"type": "string",
"value": "27912"
}
],
"buildModel": true,
"autoFillResponse": true,
"condition": [
[
{
"field": "column_id",
"logic": "eqv2",
"value": "75874"
}
]
],
"beatFlat": ["options"]
}配置解析
-
API和方法:
api: 指定要调用的API为column.list。method: 使用HTTP GET方法进行请求。
-
请求参数:
request: 包含一个字段project_id,其值为27912,这是我们需要查询的项目ID。
-
条件过滤:
condition: 设置了一个条件,要求返回的数据中column_id等于75874。
-
响应处理:
buildModel: 启用模型构建,这意味着平台会根据响应数据自动生成相应的数据模型。autoFillResponse: 自动填充响应数据到模型中。beatFlat: 将响应中的嵌套字段(如options)展平处理。
实际操作步骤
-
初始化请求: 使用上述元数据配置,通过轻易云平台发起HTTP GET请求。该请求会带上指定的项目ID,并在返回结果中筛选出符合条件的记录。
-
处理响应: 响应数据会自动填充到预先构建的数据模型中。由于启用了
autoFillResponse和buildModel,系统会自动解析并映射返回的数据,使得后续处理更加简便。 -
数据清洗与转换: 在获取到原始数据后,可以根据业务需求进行进一步的数据清洗和转换。例如,可以对特定字段进行格式化处理或计算衍生值。这一步通常使用平台提供的可视化工具或自定义脚本来完成。
-
写入目标系统: 清洗和转换后的数据可以通过轻易云平台写入到目标系统中。这一步通常涉及到另一个API调用或数据库操作,根据具体业务需求而定。
技术要点
- 异步处理:整个过程是全异步的,确保了高效的数据传输和处理。
- 多系统支持:轻易云平台支持多种异构系统的无缝对接,使得跨系统的数据集成变得简单。
- 实时监控:平台提供实时监控功能,可以随时查看数据流动和处理状态,确保每个环节都透明可见。
通过上述步骤,我们可以高效地调用班牛的接口获取所需数据,并进行必要的加工处理,为后续的数据集成打下坚实基础。
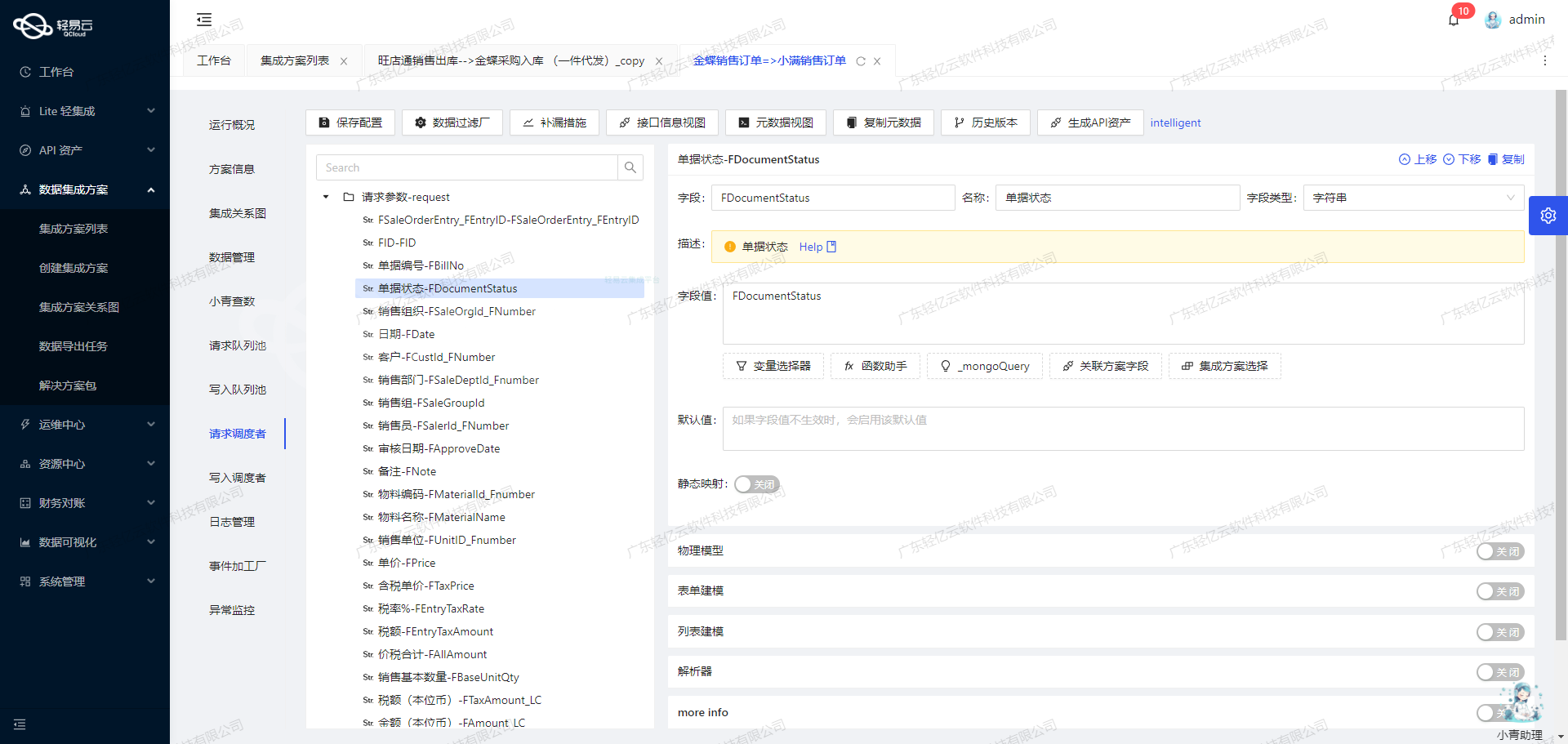
使用轻易云数据集成平台进行ETL转换并写入班牛API接口
在数据集成过程中,将源平台的数据转换为目标平台所能接收的格式是至关重要的一步。本文将重点探讨如何利用轻易云数据集成平台,将已经集成的源平台数据进行ETL转换,并最终写入班牛API接口。
数据请求与清洗
在开始数据转换之前,首先需要从源平台获取原始数据。假设我们已经完成了这一阶段,并且我们拥有了所需的供应商名称等相关信息。接下来,我们将这些数据进行清洗和预处理,以确保其格式和内容符合目标平台的要求。
数据转换
轻易云数据集成平台提供了强大的ETL(Extract, Transform, Load)工具,可以高效地将原始数据转换为目标格式。在本案例中,我们需要将清洗后的供应商名称数据转换为班牛API接口所能接收的格式。
根据元数据配置,班牛API接口的具体信息如下:
{
"api": "workflow.task.create",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}我们需要特别注意以下几点:
- API端点:
workflow.task.create - 请求方法:
POST - ID检查:
idCheck字段设置为true
数据写入
在完成数据转换后,我们需要将这些数据写入班牛API接口。以下是一个具体的实现步骤:
-
构建HTTP请求:
- 使用POST方法向班牛API发送请求。
- 确保请求体包含正确的JSON格式数据,包括供应商名称等必要信息。
-
示例代码(假设使用Python和requests库):
import requests import json # API端点 url = "https://api.banniu.com/workflow/task/create" # 构建请求头 headers = { 'Content-Type': 'application/json', 'Authorization': 'Bearer YOUR_ACCESS_TOKEN' } # 构建请求体 payload = { "supplier_name": "Example Supplier", # 其他必要字段... } # 发送POST请求 response = requests.post(url, headers=headers, data=json.dumps(payload)) # 检查响应状态 if response.status_code == 200: print("Data successfully written to BanNiu API") else: print(f"Failed to write data: {response.status_code}, {response.text}") -
错误处理与日志记录:
- 在实际应用中,务必添加错误处理机制,以捕获并记录任何可能出现的问题。
- 使用日志记录系统,确保每一次请求和响应都被详细记录,以便于后续分析和问题排查。
实时监控与优化
轻易云数据集成平台提供了实时监控功能,可以随时查看数据流动和处理状态。通过监控,可以及时发现并解决潜在问题,确保整个ETL过程高效、可靠。
在实际操作中,可能会遇到各种挑战,如网络延迟、API限流等。因此,持续优化和改进ETL流程是非常必要的。例如,可以使用批量处理来减少API调用次数,或者引入缓存机制来提高响应速度。
通过上述步骤,我们可以高效地将源平台的数据转换并写入班牛API接口,实现不同系统间的数据无缝对接。这不仅提升了业务透明度和效率,也为企业的数据管理提供了坚实保障。