SQL Server数据集成到金蝶云星空:下级部门泛微=>金蝶下级部门案例分享
在本次技术案例中,我们将探索如何使用轻易云数据集成平台,实现SQL Server与金蝶云星空的无缝对接,具体任务是将下级部门的数据从泛微系统传输至金蝶系统。本方案主要应用以下API接口进行数据操作:SQL Server获取数据的select和金蝶云星空写入数据的batchSave。
背景介绍及挑战
此次项目涉及从多个下级部门收集大量业务信息,并通过轻易云平台高效、安全地集成到统一的ERP系统——金蝶云星空。由于两者在数据结构和调用接口上存在一定差异,同时还需解决高吞吐量、大批量数据处理等问题,因此需要一套健全且灵活的数据转换和监控机制。
数据获取与映射
首先,通过定时任务调用SQL Server API select 接口抓取各个下级部门泛微系统中的最新业务信息。为保证不漏单,每次拉取前都需要记录并校对上一次成功执行的位置标志。在这个过程中,还要注意分页处理以应对海量数据的问题。此外,自定义的数据转换逻辑用于匹配SQL Server和金蝶云星空之间不同的数据格式,确保每条记录能够准确、高效地完成传输。
批量写入与异常处理
对于批量写入部分,本方案采用了金蝶云星空提供的 batchSave API,将整理好的业务信息按预设规则写入到目标数据库。同时,为提高可靠性,整体流程具备细致完善的错误重试机制,一旦网络波动或API调用失败导致异常,可自动进行多次尝试直至成功。这不仅保障了数据完整性,也提升了整体任务执行的稳定性。
实时监控与优化策略
通过集中化监控和告警系统,我们可以实时追踪每一个环节,从最初抓取、解析,到最终导出并存储于ERP,这让我们能精确掌握各项指标及其状态。如果发现任何性能瓶颈或实施偏差,可以立即采取措施调整策略,如限流控制、资源分配优化等,以进一步保障整个过程顺畅运行。
这篇文章接下来将详细描述上述各步骤的实施方式,以及运用轻易云平台特性的具体技巧,包括自定义映射设计、实时日志分析、多层次质量检测等等。敬请继续关注后续内容,在实际操作中深入了解每一步骤背后的技术原理和实践经验。
调用源系统SQL Server接口select获取并加工数据
在数据集成过程中,调用源系统的接口以获取数据是关键的第一步。本文将详细探讨如何通过轻易云数据集成平台调用SQL Server接口select来获取并加工数据。
元数据配置解析
元数据配置是实现数据请求与清洗的基础。以下是我们使用的元数据配置:
{
"api": "select",
"effect": "QUERY",
"method": "POST",
"number": "departmentname",
"id": "id",
"request": [
{
"field": "main_params",
"label": "main_params",
"type": "object",
"describe": "111",
"children": [
{
"field": "lastmoddate",
"label": "创建时间",
"type": "string",
"value": "{{DAYS_AGO_1|datetime}}"
},
{
"field": "offset",
"label": "offset",
"type": "string",
"value": "_function 0*0"
},
{
"field": "fetch",
"label": "fetch",
"type": "string",
"value": "_function 100*1"
}
]
}
],
"otherRequest": [
{
"field": "main_sql",
"label": "main_sql",
"type": "string",
"describe": "111",
"value":"select * from hrmdepartment where supdepid!='0' and canceled is null and created>=:lastmoddate ORDER BY (SELECT NULL) OFFSET :offset ROWS FETCH NEXT :fetch ROWS ONLY"
}
],
“autoFillResponse”: true
}数据请求与清洗
在这个阶段,我们主要关注如何通过API接口从SQL Server中获取所需的数据,并进行初步清洗。
-
API调用方式:
api:selecteffect:QUERYmethod:POST
-
请求参数:
main_params:包含三个子参数:lastmoddate:表示创建时间,使用动态值{{DAYS_AGO_1|datetime}},即一天前的日期时间。offset:分页偏移量,初始值为0。fetch:每次获取的数据条数,设置为100。
-
SQL查询语句:
- 在
otherRequest中定义了主要的SQL查询语句:select * from hrmdepartment where supdepid!='0' and canceled is null and created>=:lastmoddate ORDER BY (SELECT NULL) OFFSET :offset ROWS FETCH NEXT :fetch ROWS ONLY - 此查询语句用于从部门表中筛选出未取消且上级部门ID不为0,并且创建时间在指定日期之后的数据。通过OFFSET和FETCH实现分页查询。
- 在
数据转换与写入
虽然本文重点不在于数据转换与写入,但为了完整性简要提及,这些步骤通常包括:
- 数据格式转换:将SQL Server返回的数据转换为目标系统所需的格式。
- 数据映射:根据业务需求对字段进行映射和转换。
- 数据写入:将处理后的数据写入目标系统,如金蝶下级部门。
实际案例分析
假设我们需要从SQL Server中的hrmdepartment表中获取最近一天内新增的部门信息,并分页处理。以下是具体步骤:
-
配置请求参数:
- 设置
lastmoddate为当前日期前一天。 - 设置
offset为0,表示从第一条记录开始。 - 设置
fetch为100,表示每次获取100条记录。
- 设置
-
执行SQL查询: 使用上述配置,通过POST方法调用API接口,将生成如下SQL查询语句:
select * from hrmdepartment where supdepid!='0' and canceled is null and created>='2023-10-01' ORDER BY (SELECT NULL) OFFSET 0 ROWS FETCH NEXT 100 ROWS ONLY -
处理返回结果: 平台会自动填充响应结果(autoFillResponse: true),并将其传递到下一步的数据处理流程中。
通过这种方式,我们可以高效地从源系统中获取所需的数据,并进行初步清洗,为后续的数据转换与写入打下坚实基础。
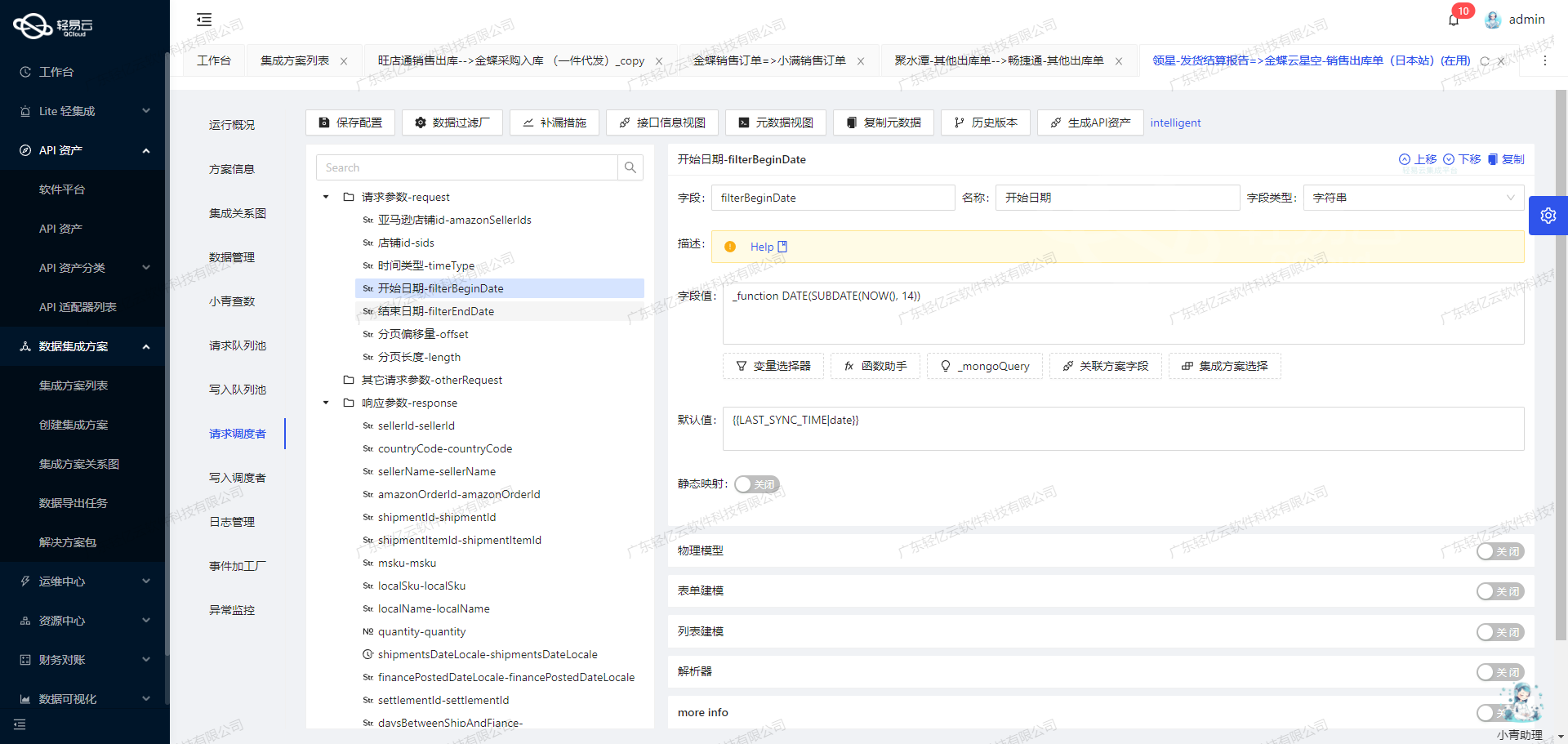
使用轻易云数据集成平台实现数据转换与写入金蝶云星空API接口
在数据集成生命周期的第二步,我们需要将已经集成的源平台数据进行ETL(Extract, Transform, Load)转换,并转为目标平台金蝶云星空API接口所能够接收的格式,最终写入目标平台。以下是详细的技术步骤和配置说明。
数据请求与清洗
首先,我们需要从源系统(泛微)中提取部门相关的数据。提取的数据包括部门ID、编码、名称、使用组织、创建组织、上级部门和助记码等字段。这些字段将通过轻易云数据集成平台进行清洗和转换,以符合金蝶云星空API的要求。
数据转换
在数据转换阶段,我们利用元数据配置对提取的数据进行处理。以下是元数据配置中的关键字段及其解析方法:
- FDEPTID(部门id):这是一个字符串类型的字段,用于标识部门的唯一ID。
- FNumber(编码):同样是字符串类型,用于表示部门的编码。
- FName(名称):这是一个复杂字段,需要根据不同语言环境进行解析。例如:
[ {"Key": 1033, "Value": "OA_{second_name}"}, {"Key": 2052, "Value": "OA_{first_name}"}, {"Key": 3076, "Value": "OA_{third_name}"} ]这里使用了
ConvertJson解析器,将不同语言环境下的名称进行转换。 - FUseOrgId(使用组织) 和 FCreateOrgId(创建组织):这两个字段都需要映射到目标系统中的组织ID,使用
ConvertObjectParser解析器,并通过subcompanyid1进行映射。 - FParentID(上级部门):该字段通过查找集合来确定上级部门的编码,使用
ConvertObjectParser解析器。 - FHelpCode(助记码):直接从源系统中获取并传递到目标系统。
数据写入
在完成数据转换后,我们需要将处理后的数据写入到金蝶云星空中。具体操作如下:
-
API接口调用:
- API:
batchSave - Method:
POST - Effect:
EXECUTE
- API:
-
请求参数配置:
FormId: 必须填写金蝶的表单ID,例如:BD_DepartmentOperation: 操作类型,这里为BatchSaveIsAutoSubmitAndAudit: 是否自动提交和审核,布尔值,默认为trueIsVerifyBaseDataField: 是否验证所有基础资料有效性,布尔值,默认为false
-
其他配置项:
rowsKey: 定义数组键名rows: 每次批量保存的数据行数method: 批量保存的方法,这里为batchArraySave
通过上述配置,我们可以确保从泛微系统提取的数据经过清洗和转换后,能够符合金蝶云星空API接口的要求,并顺利写入目标平台。
实际应用案例
在实际应用中,我们可能会遇到以下场景:
- 从泛微系统中提取多个部门的信息,包括其层级关系。
- 利用轻易云数据集成平台对这些信息进行批量处理,将其转换为金蝶云星空所需的格式。
- 调用金蝶云星空API接口,将处理后的数据批量写入到目标系统中。
例如,一个典型的数据请求可能包含以下内容:
{
"api": "batchSave",
"method": "POST",
"request": [
{"field":"FDEPTID","value":"D001"},
{"field":"FNumber","value":"D001"},
{"field":"FName","value":[{"Key":1033,"Value":"OA_Sales"},{"Key":2052,"Value":"销售部"},{"Key":3076,"Value":"销售部"}]},
{"field":"FUseOrgId","value":"ORG001"},
{"field":"FCreateOrgId","value":"ORG001"},
{"field":"FParentID","value":"D000"},
{"field":"FHelpCode","value":"XS"}
],
"otherRequest": {
"FormId": "BD_Department",
"Operation": "BatchSave",
"IsAutoSubmitAndAudit": true,
"IsVerifyBaseDataField": false
}
}通过上述配置和操作,我们可以确保从源系统到目标系统的数据集成过程高效且无缝地完成。这不仅提升了业务透明度和效率,也确保了数据的一致性和准确性。