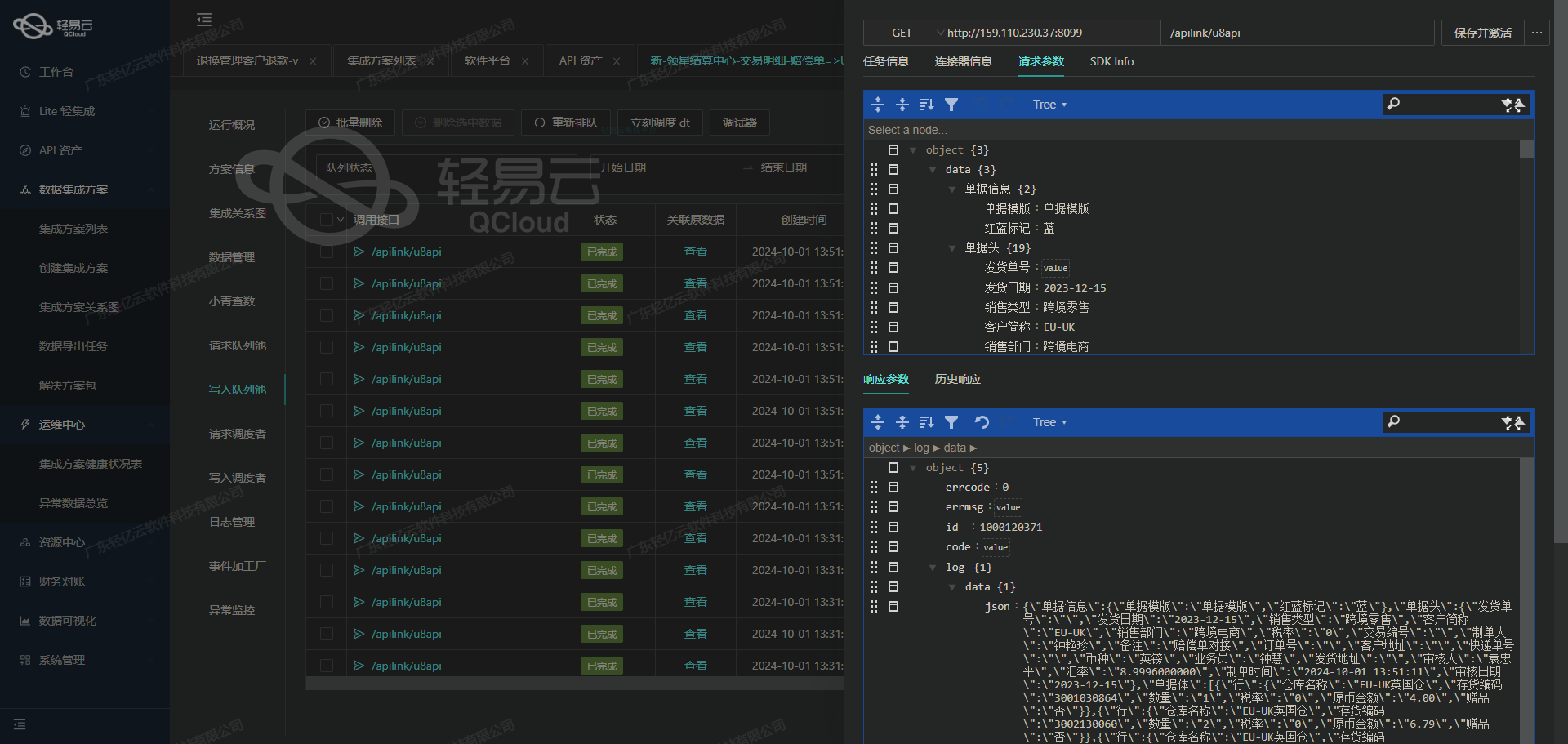
案例分享:聚水潭数据集成到金蝶云星空
在现代企业信息系统中,数据的无缝对接和高效处理是实现业务自动化与智能决策的重要基础。本文将深入探讨一个具体的系统集成案例,即如何通过轻易云数据集成平台完成聚水潭盘盈单的数据导入到金蝶云星空其他入库单,从而确保两个系统间的数据一致性和完整性。
聚水潭-盘盈单-->金蝶-其他入库单:从API获取到批量写入
该方案利用了聚水潭提供的/open/inventory/count/query API接口进行数据抓取,并使用金蝶云星空的batchSave API接口进行批量写入。在实施过程中,面临着确保不漏单、大量数据快速处理、接口限流等多重技术挑战。
-
定时可靠抓取聚水潭接口数据 首先,通过轻易云平台配置定时任务,以分钟级频率调用聚水潭的库存盘盈查询接口。这一步确保我们能够实时获取最新的数据,有效防止任何遗漏。同时,结合日志记录功能,可以对每次调用情况进行监控与审计。
-
分页与限流处理 由于API调用次数限制及返回结果分页机制,我们设计了策略来逐页拉取并合并所有盘盈记录。在这一过程中,还加入了重试机制以应对可能出现的网络抖动或服务异常,提高整体运行的稳定性和连续性。
-
格式转换与映射 获取到原始数据后,需要将其转换为符合金蝶云星空要求的数据格式。借助轻易云可视化映射工具,我们可以灵活定义字段对应关系,以及必要的数据清洗逻辑,从而使得不同系统间复杂的数据结构差异迎刃而解。
-
批量写入至金蝶云星空 转换后的数据接下来通过
batchSaveAPI上传至金蝶。为了优化性能和减小压力,每次操作都控制在合理条目数内,同时遵循幂等性的编程原则,对已成功传输的数据做标记避免重复插入。此外,我们还设置了错误捕获和重试策略,保证即便发生偶然失败,也不会影响整体流程顺利推进。 -
实时监控与异常处理机制 联合使用轻易云自带监控工具,实现全过程透明管理。一旦检测到异常,如网络故障或目标数据库暂时不可用,可立即通知相关人员采取措施,同时启动预设恢复程序减少影响范围,这些都显著提升了整个解决方案的可靠性和稳健性。
结语部分我们将在
调用聚水潭接口获取并加工数据的技术案例
在轻易云数据集成平台中,生命周期的第一步是调用源系统接口获取数据,并对其进行初步加工。本文将详细探讨如何通过调用聚水潭接口/open/inventory/count/query来实现这一过程。
API接口配置
首先,我们需要了解聚水潭提供的API接口/open/inventory/count/query。该接口采用POST方法,主要用于查询库存盘点单。以下是元数据配置的详细信息:
{
"api": "/open/inventory/count/query",
"method": "POST",
"number": "io_id",
"id": "io_id",
"buildModel": true,
"request": [
{
"field": "page_index",
"label": "开始页码",
"type": "string",
"describe": "第几页,从第一页开始,默认1",
"value": "1"
},
{
"field": "page_size",
"label": "每页条数",
"type": "string",
"describe": "每页多少条,默认30,最大50",
"value": "50"
},
{
"field": "modified_begin",
"label": "修改开始时间",
"type": "datetime",
"describe": "修改起始时间,和结束时间必须同时存在,时间间隔不能超过七天,与线上单号不能同时为空",
"value": "{{LAST_SYNC_TIME|datetime}}"
},
{
"field": "modified_end",
"label": "修改结束时间",
"type": "datetime",
"describe": "修改结束时间,和起始时间必须同时存在,时间间隔不能超过七天,与线上单号不能同时为空",
"value": "{{CURRENT_TIME|datetime}}"
},
{
"field": "status",
...请求参数解析
- page_index: 开始页码,从第一页开始,默认值为1。
- page_size: 每页条数,默认30条,最大50条。
- modified_begin: 修改开始时间,与结束时间必须同时存在,且时间间隔不能超过七天。
- modified_end: 修改结束时间,与开始时间必须同时存在。
- status: 单据状态,如Confirmed(生效)、WaitConfirm(待审核)、Creating(草拟)、Archive(归档)、Cancelled(作废)。
这些参数确保了我们能够灵活地分页获取数据,并根据需要过滤特定状态的单据。
数据过滤与清洗
在获取到原始数据后,我们需要对其进行初步过滤和清洗。根据元数据配置中的条件,我们只保留数量大于0的记录:
"condition_bk":[[{"field":"items.qty","logic":"gt","value":"0"}]]这一步骤确保了我们只处理有效的数据,提高了后续处理的效率。
数据转换与写入
经过初步清洗后的数据,需要进行转换以适应目标系统的格式要求。轻易云平台提供了强大的数据转换功能,可以将源系统的数据字段映射到目标系统所需的字段格式。例如,将聚水潭的盘盈单转换为金蝶系统中的其他入库单。
"beatFlat":["items"]通过这一配置,我们可以将嵌套结构的数据展平,使其更容易被目标系统接收和处理。
实践案例
假设我们需要从聚水潭中获取最近一周内所有状态为Confirmed且数量大于0的盘盈单,并将其转换为金蝶系统中的其他入库单。以下是一个具体操作步骤:
-
配置API请求参数:
{ ... {"field":"modified_begin","value":"2023-10-01T00:00:00"}, {"field":"modified_end","value":"2023-10-07T23:59:59"}, {"field":"status","value":"Confirmed"} ... } -
调用API并获取数据:
response = requests.post( url="https://api.jushuitan.com/open/inventory/count/query", json=request_payload ) data = response.json() -
过滤并清洗数据:
filtered_data = [item for item in data['items'] if item['qty'] > 0] -
转换并写入目标系统:
transformed_data = transform_to_kingdee_format(filtered_data) write_to_kingdee(transformed_data)
通过上述步骤,我们实现了从聚水潭到金蝶系统的数据无缝对接。这不仅提高了业务流程的自动化程度,也确保了数据的一致性和准确性。
以上就是调用聚水潭接口获取并加工数据的详细技术案例,希望能为您的实际操作提供参考和帮助。
使用轻易云数据集成平台实现聚水潭盘盈单到金蝶云星空其他入库单的ETL转换
在数据集成生命周期中,将源平台的数据转换为目标平台所能接收的格式是至关重要的一步。本文将详细探讨如何利用轻易云数据集成平台,将聚水潭盘盈单的数据转换为金蝶云星空其他入库单API接口所能接收的格式,并最终写入目标平台。
元数据配置解析
首先,我们来看一下元数据配置,这是整个ETL过程的核心。以下是关键字段及其配置解析:
-
基本请求参数
api: "batchSave" - 指定调用金蝶云星空的批量保存接口。method: "POST" - 使用POST方法提交数据。idCheck: true - 启用ID检查,确保数据唯一性。
-
请求主体字段
FBillNo: 单据编号,格式为{items_io_id}-TEST,表示从源数据中提取并拼接一个固定字符串。FBillTypeID: 单据类型,固定值 "QTRKD01_SYS",并使用ConvertObjectParser转换对象。FStockOrgId: 库存组织,从{brand}提取并通过映射关系进行转换。FStockDirect: 库存方向,固定值 "GENERAL"。FDEPTID: 部门,根据{brand}进行条件判断并赋值。FDate: 日期,从{io_date}提取。FOwnerTypeIdHead: 货主类型,固定值 "BD_OwnerOrg"。FOwnerIdHead: 货主,从{brand}提取并通过映射关系进行转换。FNOTE: 备注,从{remark}提取。
-
明细信息字段 明细信息字段是一个数组,每个子项代表一个明细行:
FMATERIALID: 物料编码,从{items_sku_id}提取并使用ConvertObjectParser转换对象。FQty: 实收数量,从{items_qty}提取。FSTOCKID: 收货仓库,通过_findCollection方法根据多个条件进行查找和赋值。FEntryNote: 备注,可以为空或根据需求填写。FOWNERTYPEID: 货主类型,固定值 "BD_OwnerOrg"。FOWNERID: 货主,从{brand}提取并通过映射关系进行转换。
-
其他请求参数 除了主体字段外,还需要一些其他参数来完成请求:
FormId: 固定值 "STK_MISCELLANEOUS",表示业务对象表单ID。IsVerifyBaseDataField: 验证基础资料有效性,布尔值 false(非必录)。Operation: 执行的操作,固定值 "Save"。IsAutoSubmitAndAudit: 是否自动提交并审核,布尔值 true。
数据处理逻辑
在实际操作中,我们需要按照以下步骤进行数据处理:
-
数据提取与清洗 从聚水潭系统提取盘盈单数据,并对其进行初步清洗和验证。这一步主要是确保源数据的完整性和准确性。
-
字段映射与转换 根据元数据配置,将清洗后的源数据字段映射到金蝶云星空API所需的字段。这里需要特别注意的是使用
ConvertObjectParser等工具进行对象转换,以及条件判断逻辑,如部门字段的赋值。 -
构建请求体 将映射后的字段构建成符合金蝶云星空API要求的JSON请求体。这里需要按照元数据配置中的结构来组织数据,包括头部信息和明细信息。
-
发送请求 使用POST方法将构建好的请求体发送到金蝶云星空API接口,并处理返回结果。根据返回结果判断操作是否成功,并记录日志以备后续审计和问题排查。
示例代码
以下是一个示例代码片段,用于展示如何构建请求体并发送请求:
import requests
import json
# 构建请求头
headers = {
'Content-Type': 'application/json'
}
# 构建请求体
request_body = {
"FormId": "STK_MISCELLANEOUS",
"IsVerifyBaseDataField": False,
"Operation": "Save",
"IsAutoSubmitAndAudit": True,
"Model": {
"FBillNo": f"{source_data['items_io_id']}-TEST",
"FBillTypeID": {"FNumber": "QTRKD01_SYS"},
"FStockOrgId": {"FNumber": source_data['brand']},
# ... 其他字段
"FEntity": [
{
"FMATERIALID": {"FNumber": item['items_sku_id']},
# ... 明细信息
}
for item in source_data['list']
]
}
}
# 发送POST请求
response = requests.post(
url="https://api.kingdee.com/batchSave",
headers=headers,
data=json.dumps(request_body)
)
# 处理响应
if response.status_code == 200:
print("Data successfully saved to Kingdee Cloud.")
else:
print(f"Failed to save data: {response.text}")以上代码展示了如何从源数据中提取必要信息,并按照元数据配置构建JSON请求体,然后通过HTTP POST方法将其发送到金蝶云星空API接口。