查询金蝶物料:金蝶云星空到轻易云数据集成案例
在企业信息化管理的实际应用中,跨系统的数据对接和集成演变为关键业务需求。本文将分享一个技术案例,展示如何通过轻易云数据集成平台高效地实现金蝶云星空的物料查询集成。我们将重点聚焦于如何调用关键API接口、处理分页和限流问题,以及确保数据流转可靠性。
本次案例中,我们使用了金蝶云星空提供的executeBillQuery接口,用以获取物料信息,并利用轻易云集成平台进行批量写入与实时监控。在具体实施过程中,需要特别注意以下几个方面:
-
调用executeBillQuery接口:
- 该接口用于从金蝶云星空拉取最新的物料数据,包括产品代码、名称及规格等核心字段。
- 为确保不漏单且能及时抓取最新数据,我们设计了定时任务,每隔一段时间自动触发此API。
-
分页与限流处理:
- 由于大多数企业级系统对API请求频率有所限制,仅靠简单调用显然不够。
- 我们采用分批次拉取策略,通过设置适当的页码参数与条目数,逐步获取完整的数据集合。同时,借助轻易云的平台能力,对超出阈值请求进行合理排队处理,从而避免封锁风险。
-
数据格式差异处理:
- 金蝶与轻易不同平台间存在标准字段命名规则差异,为此我们进行了定制化的数据映射配置。
- 在元数据配置阶段,通过灵活定义转换规则,把源端结构无缝映射到目标端,大大简化后续操作步骤。
-
异常处理与错误重试机制:
- 数据传输过程中的网络波动或意外断连会导致部分操作失败,因此需要具备强健的容错机制。
- 采用多层校验捕捉异常并记录日志,使得每一次失败请求都能够被检测修复。配合重试策略,可以有效提升整体成功率并降低运维成本。
-
实时监控与日志记录:
- 借助平台内置功能模块,我们实现了针对整个流程链路状态的全程透明跟踪。一旦出现任何故障迹象,可迅速定位根因并加以处置,有力保障业务连续性。
通过上述技术方案,我们不仅保证了从金蝶到轻易之间的大量参数传递准确无误,同时也极大提高了各环节响应速度与稳定性。这些实用经验对于类似场景有重要参考价值,将在下文
使用轻易云数据集成平台调用金蝶云星空接口executeBillQuery获取并加工数据
在数据集成的生命周期中,第一步是从源系统获取数据。本文将详细探讨如何使用轻易云数据集成平台调用金蝶云星空接口executeBillQuery来获取并加工物料数据。
接口配置与请求参数
轻易云数据集成平台提供了全透明可视化的操作界面,使得配置和调用API接口变得简单直观。以下是元数据配置中的关键参数:
- api:
executeBillQuery - method:
POST - FormId:
BD_MATERIAL(业务对象表单Id)
请求参数配置如下:
{
"FMasterId": "id",
"FNumber": "编码",
"FName": "名称",
"FSpecification": "规格型号",
"FOldNumber": "旧物料编码",
...
}这些字段涵盖了物料的基本信息、属性、状态等多个维度,确保我们能够全面获取所需的数据。
请求示例
在实际操作中,我们需要构建一个POST请求,包含上述字段及其他必要的参数。以下是一个示例请求体:
{
"FormId": "BD_MATERIAL",
"FieldKeys": [
"FMasterId",
"FNumber",
"FName",
...
],
"FilterString": "FUseOrgId.fnumber='100' and FModifyDate >='{{LAST_SYNC_TIME|dateTime}}' and F_PAEZ_Base2!=''",
"Limit": 2000,
"StartRow": "{PAGINATION_START_ROW}"
}数据清洗与转换
在获取到原始数据后,下一步是进行数据清洗和转换。这一步骤确保数据符合目标系统的要求,并去除冗余或不一致的数据。
- 字段映射:根据元数据配置,将金蝶云星空返回的数据字段映射到目标系统所需的字段。例如,将
FMasterId映射为id,将FNumber映射为编码。 - 数据格式转换:根据目标系统的需求,对某些字段进行格式转换。例如,将日期格式从金蝶云星空的格式转换为目标系统所需的标准格式。
- 过滤无效数据:根据业务规则,过滤掉不符合条件的数据。例如,剔除禁用状态为“禁用”的物料。
实时监控与错误处理
轻易云数据集成平台提供实时监控功能,可以实时查看每个环节的数据流动和处理状态。如果在调用接口或处理数据过程中出现错误,可以通过平台提供的日志和监控工具快速定位并解决问题。
例如,如果接口返回错误信息或超时,可以通过以下步骤进行排查:
- 检查请求参数:确保所有必填参数正确填写,并且没有遗漏。
- 查看日志:通过平台日志查看具体错误信息,例如网络问题、权限不足等。
- 重试机制:对于临时性错误,可以设置重试机制,在一定时间间隔后重新发起请求。
总结
通过以上步骤,我们可以高效地使用轻易云数据集成平台调用金蝶云星空接口executeBillQuery获取并加工物料数据。这不仅简化了跨系统的数据集成过程,还提高了业务透明度和效率。在实际项目中,根据具体需求灵活调整配置和处理逻辑,可以进一步优化集成效果。
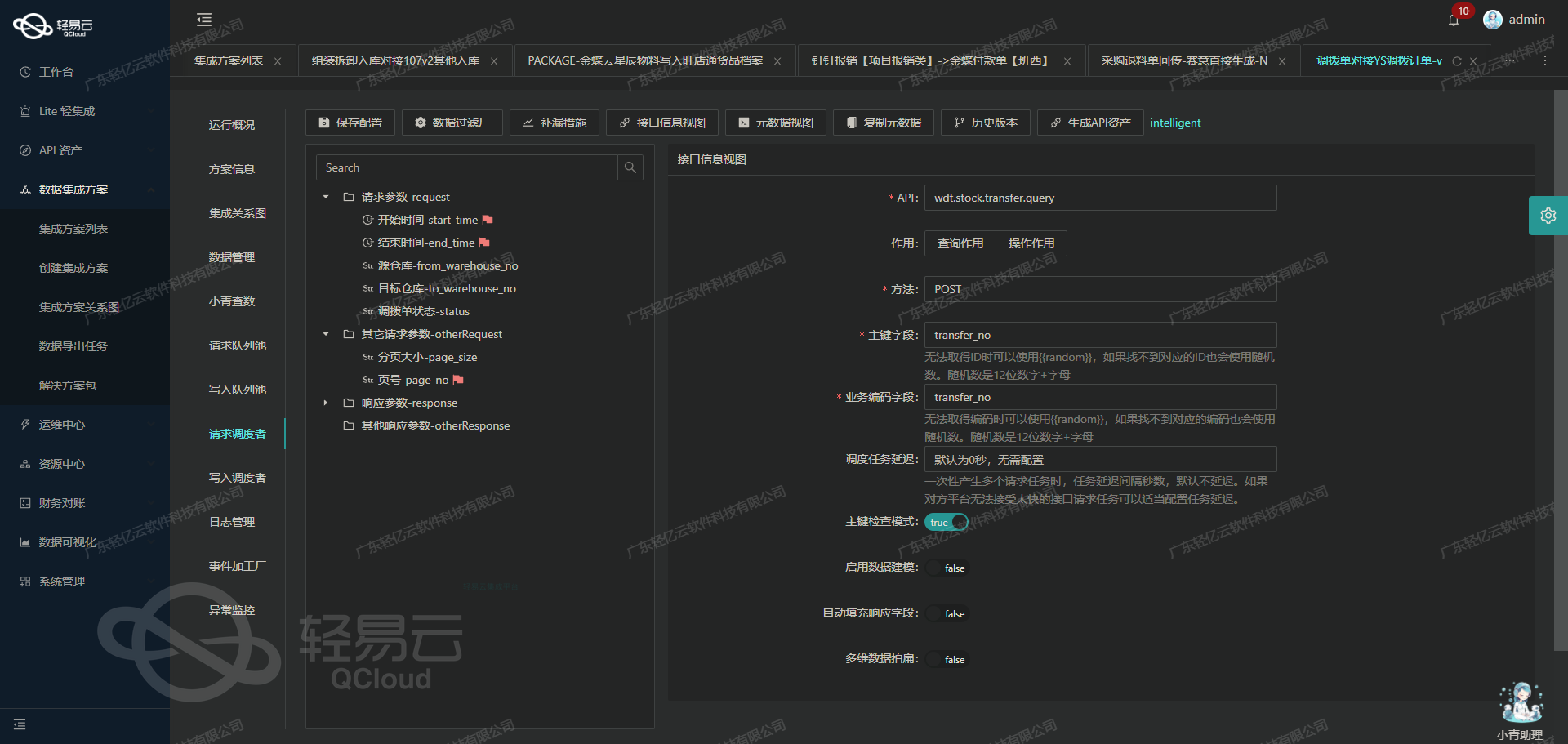
轻易云数据集成平台ETL转换与写入技术案例
在轻易云数据集成平台中,完成数据请求与清洗后,接下来需要将这些数据进行ETL转换,并最终写入目标平台。本文将详细探讨如何通过配置元数据,将源平台的物料数据转换为目标平台能够接收的格式,并通过API接口写入目标平台。
数据转换与写入的元数据配置
在本案例中,我们将使用如下元数据配置:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}这个配置表明我们要调用目标平台的“写入空操作”API接口,使用HTTP POST方法执行操作,并且在写入前需要进行ID检查。
ETL转换过程
ETL(Extract, Transform, Load)过程是数据集成中的关键步骤。以下是具体步骤:
- 提取(Extract):从金蝶系统中提取物料数据。这一步已经在生命周期的第一阶段完成。
- 转换(Transform):将提取的数据转换为目标平台所需的格式。这包括字段映射、数据类型转换、值替换等。
- 加载(Load):通过API接口将转换后的数据加载到目标平台。
转换规则与实现
在进行ETL转换时,需要根据目标平台的要求对数据进行处理。以下是一些常见的转换规则及其实现方式:
-
字段映射:将源平台的数据字段映射到目标平台的数据字段。例如,金蝶系统中的“物料编码”可能需要映射为目标平台中的“material_code”。
def map_fields(source_data): return { "material_code": source_data["物料编码"], "material_name": source_data["物料名称"], # 其他字段映射 } -
数据类型转换:确保源平台的数据类型符合目标平台的要求。例如,将字符串类型的日期转换为日期对象。
from datetime import datetime def convert_date(date_str): return datetime.strptime(date_str, "%Y-%m-%d") def transform_data(source_data): transformed_data = map_fields(source_data) transformed_data["created_date"] = convert_date(source_data["创建日期"]) return transformed_data -
值替换:根据业务规则对某些字段值进行替换或计算。例如,将状态码从数字转换为描述性文本。
def replace_status_code(status_code): status_mapping = { 1: "有效", 0: "无效" } return status_mapping.get(status_code, "未知") def transform_data_with_status(source_data): transformed_data = transform_data(source_data) transformed_data["status"] = replace_status_code(source_data["状态码"]) return transformed_data
数据写入
完成数据转换后,下一步是通过API接口将数据写入目标平台。根据元数据配置,我们需要使用HTTP POST方法调用“写入空操作”API接口。
-
构建请求体:将转换后的数据构建为API请求体。
import json def build_request_body(transformed_data): return json.dumps(transformed_data) -
发送请求:使用HTTP库发送POST请求,并处理响应。
import requests def send_post_request(api_url, request_body): headers = {"Content-Type": "application/json"} response = requests.post(api_url, data=request_body, headers=headers) if response.status_code == 200: print("Data successfully written to target platform.") else: print(f"Failed to write data: {response.text}") api_url = "https://api.targetplatform.com/execute" transformed_data = transform_data_with_status(source_data) request_body = build_request_body(transformed_data) send_post_request(api_url, request_body)
ID检查
根据元数据配置中的idCheck参数,在写入前需要进行ID检查,以确保不会重复插入相同的数据。这可以通过查询目标平台现有记录来实现,如果存在相同ID则更新记录,否则插入新记录。
def check_id_exists(api_url, material_id):
response = requests.get(f"{api_url}/{material_id}")
return response.status_code == 200
def upsert_record(api_url, transformed_data):
material_id = transformed_data["material_code"]
if check_id_exists(api_url, material_id):
# 更新记录
response = requests.put(f"{api_url}/{material_id}", data=build_request_body(transformed_data))
else:
# 插入新记录
response = requests.post(api_url, data=build_request_body(transformed_data))
if response.status_code in [200, 201]:
print("Data successfully upserted to target platform.")
else:
print(f"Failed to upsert data: {response.text}")
upsert_record(api_url, transformed_data)以上代码展示了如何进行ID检查并执行插入或更新操作,以确保数据的一致性和完整性。通过这种方式,可以有效地避免重复插入和覆盖已有记录的问题。
总结来说,通过合理配置元数据并实施ETL转换和API调用,可以高效地实现不同系统间的数据集成,确保业务流程的顺畅运行。