领星ERP数据集成到用友U8的技术案例分享
在企业信息化建设中,数据集成是实现系统间高效协作的关键环节。本次案例将聚焦于如何通过轻易云数据集成平台,将领星ERP中的FBA补货入库数据无缝对接到用友U8系统,生成调拨单【国外->FBA】。这一过程不仅需要确保数据的准确性和时效性,还需处理多种技术挑战,如接口调用、数据转换、异常处理等。
方案概述
本次集成方案命名为“领星-FBA补货入库-->U8-调拨单【国外->FBA】”,旨在通过API接口实现两个系统的数据互通。具体来说,我们将利用领星ERP提供的API /cost/center/api/cost/stream 获取补货入库数据,并通过用友U8的API /apilink/u8api 将这些数据写入生成调拨单。
技术要点
-
高吞吐量的数据写入能力: 为了应对大规模的数据处理需求,本方案支持高吞吐量的数据写入,使得大量补货入库记录能够快速被集成到用友U8中,提升整体业务效率。
-
实时监控与告警系统: 集成过程中,实时监控和告警系统至关重要。我们配置了集中式监控和告警机制,实时跟踪每个数据集成任务的状态和性能,一旦出现异常情况,能够及时响应并进行处理。
-
自定义数据转换逻辑: 由于领星ERP与用友U8之间存在一定的数据格式差异,我们设计了自定义的数据转换逻辑,以适应特定业务需求。这确保了从源头获取的数据能准确映射到目标系统中所需的格式。
-
分页与限流处理: 在调用领星ERP接口时,为了避免因大量请求导致服务器压力过大,我们采用了分页和限流策略。这不仅保证了接口调用的稳定性,也提高了整体数据抓取效率。
-
异常处理与错误重试机制: 数据集成过程中难免会遇到各种异常情况。为了确保任务顺利完成,我们设计了一套完善的异常处理与错误重试机制。一旦某条记录写入失败,系统会自动进行重试,并记录详细日志以便后续分析和优化。
-
可视化的数据流设计工具: 本方案采用可视化的数据流设计工具,使得整个数据集成过程更加直观和易于管理。从源头获取、转换、传输到目标写入,每一步都清晰可见,有助于快速定位问题并进行调整。
通过以上技术要点,本次案例展示了如何有效地将领星ERP中的FBA补货入库数据成功对接到用友U8系统,实现跨平台的数据同步与业务协同。在接下来的章节中,我们将详细介绍具体实施步骤及相关配置细节。
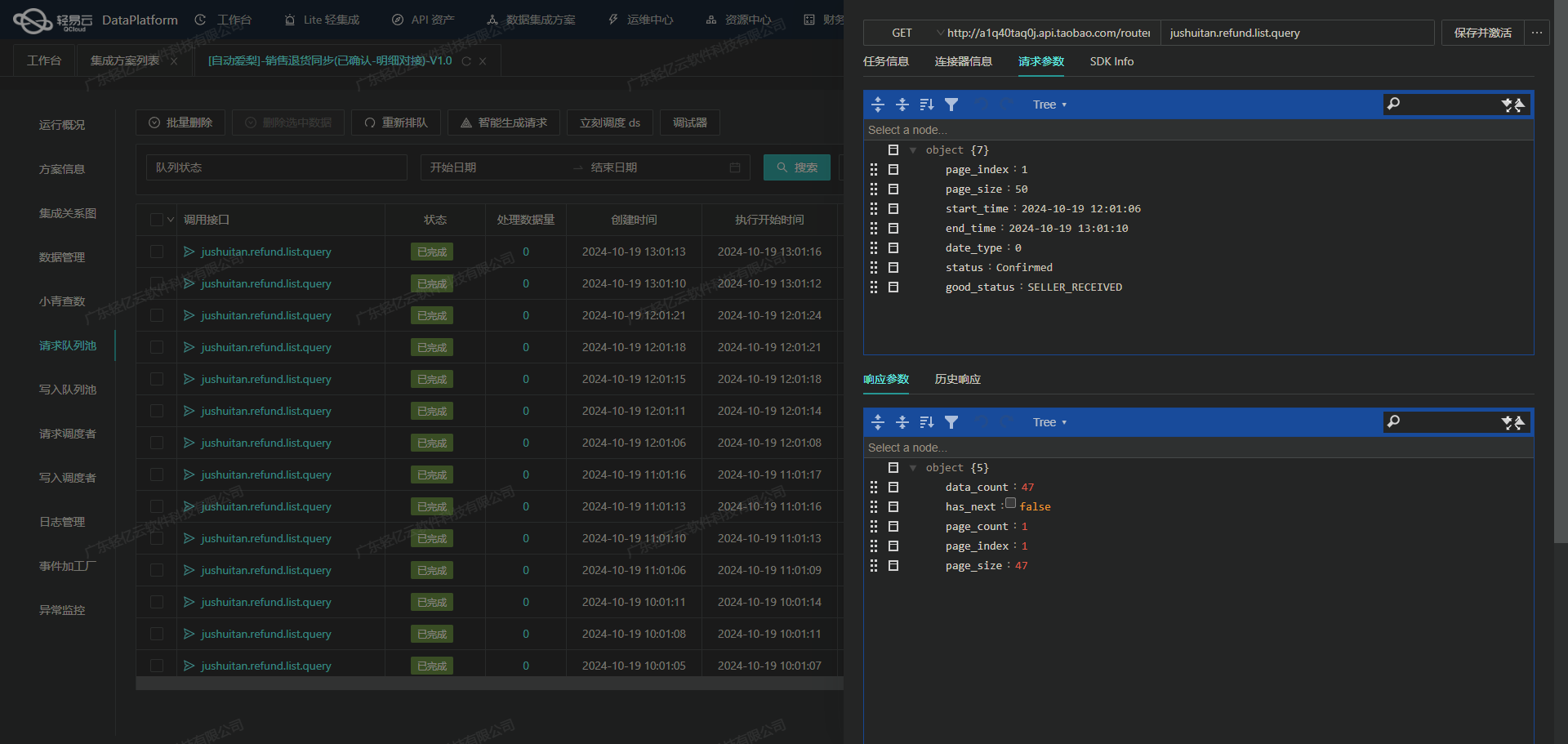
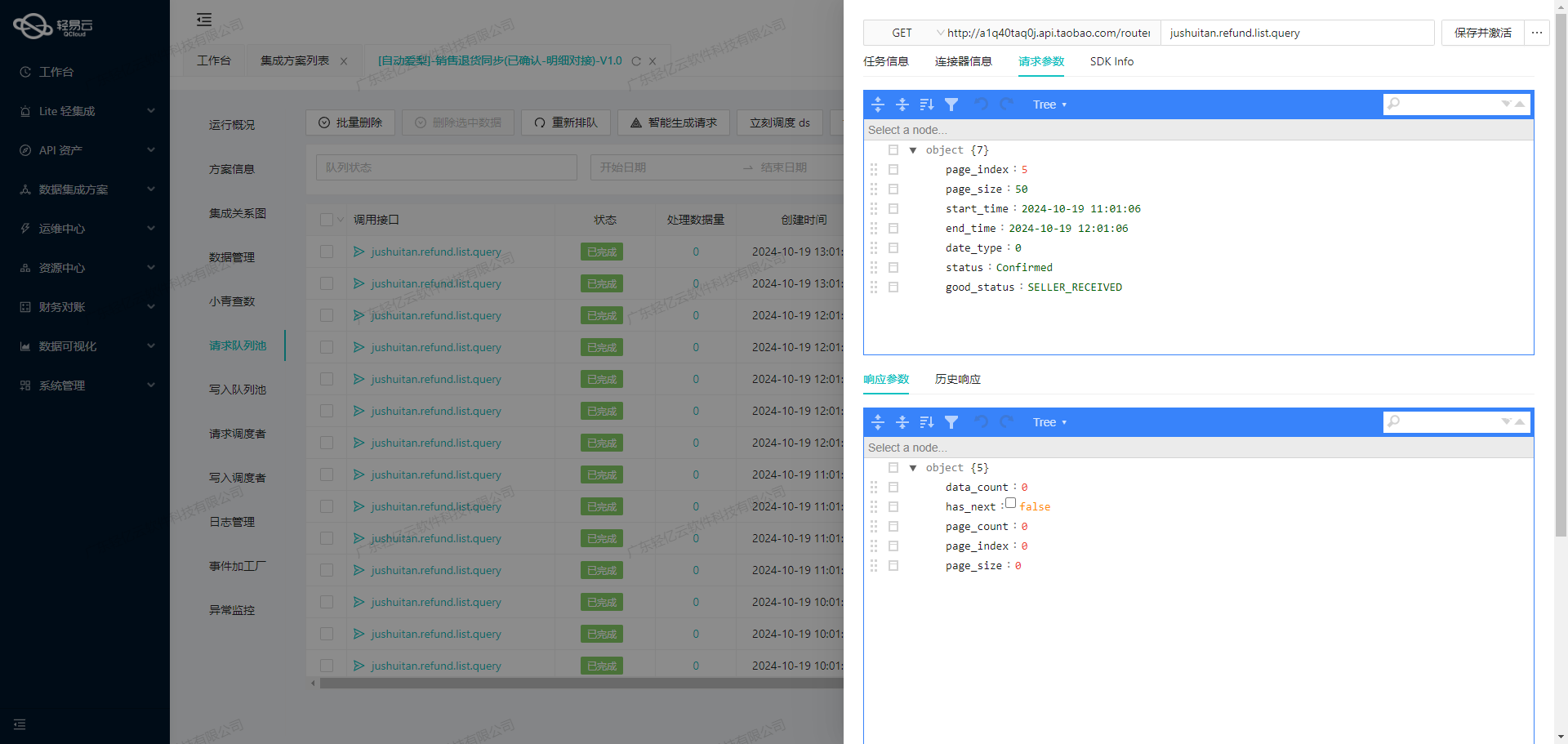
调用领星ERP接口/cost/center/api/cost/stream获取并加工数据
在轻易云数据集成平台中,调用源系统领星ERP接口是数据集成生命周期的第一步。本文将详细探讨如何通过配置元数据来实现对领星ERP接口/cost/center/api/cost/stream的数据请求与清洗。
接口调用与元数据配置
首先,我们需要理解接口的基本信息和参数配置。根据提供的元数据,接口采用POST方法进行调用,主要用于查询(effect为QUERY)。以下是关键字段及其解析方式:
- wh_names、shop_names、skus、mskus等字段均为字符串类型,通过逗号分隔符转换为数组。
- disposition_types和business_types字段同样为字符串类型,但具有特定的业务含义,如库存属性和出入库类型。
- query_type用于指定日期查询类型,例如库存动作日期或结算日期。
- start_date和end_date定义了查询的时间范围,不允许跨月。
- offset和length用于分页控制,默认值分别为1和200。
这些字段在请求体中的具体配置如下:
{
"wh_names": "仓库A,仓库B",
"shop_names": "店铺1,店铺2",
"skus": "SKU001,SKU002",
"mskus": "MSKU001,MSKU002",
...
}数据请求与清洗
在实际操作中,轻易云平台会根据上述元数据自动生成请求体,并发送到领星ERP接口。返回的数据需要经过清洗,以确保其符合后续处理要求。
字符串转数组解析
例如,对于wh_names字段,其值可能是一个以逗号分隔的字符串。在接收到响应后,需要将其解析为数组格式。这可以通过自定义解析逻辑实现:
def StringToArray(value, delimiter=","):
return value.split(delimiter)日期格式处理
对于日期相关字段,如start_date和end_date,需要确保它们符合指定格式(Y-m-d)。这可以通过预先设置默认值来实现,例如使用模板变量{{DAYS_AGO_3|date}}表示三天前的日期。
分页与限流处理
由于API可能返回大量数据,为了避免超时或性能问题,需要进行分页处理。通过设置offset和length参数,可以控制每次请求的数据量。例如,每次请求200条记录,并逐页获取:
{
"offset": "1",
"length": "200"
}当处理完一页数据后,将偏移量增加1,再次发送请求,直到所有数据都被获取完毕。
数据转换与写入准备
在完成初步的数据清洗后,需要对数据进行进一步转换,以适应目标系统(如用友U8)的需求。这包括但不限于:
- 数据格式转换:确保不同系统间的数据结构一致性。
- 字段映射:将源系统中的字段映射到目标系统对应的字段上。
- 异常处理:捕获并处理可能出现的数据异常情况。
例如,将领星ERP中的业务编号(business_number)映射到用友U8中的相应字段,并确保唯一性检查(idCheck: true)。
实时监控与日志记录
为了保证整个过程的透明度和可追溯性,轻易云平台提供了实时监控和日志记录功能。每个步骤都会生成详细的日志,包括API调用状态、响应时间、错误信息等。这些信息有助于快速定位问题并进行修复。
综上所述,通过合理配置元数据并利用轻易云平台强大的集成功能,可以高效地从领星ERP接口获取并加工所需数据,为后续的数据转换与写入打下坚实基础。
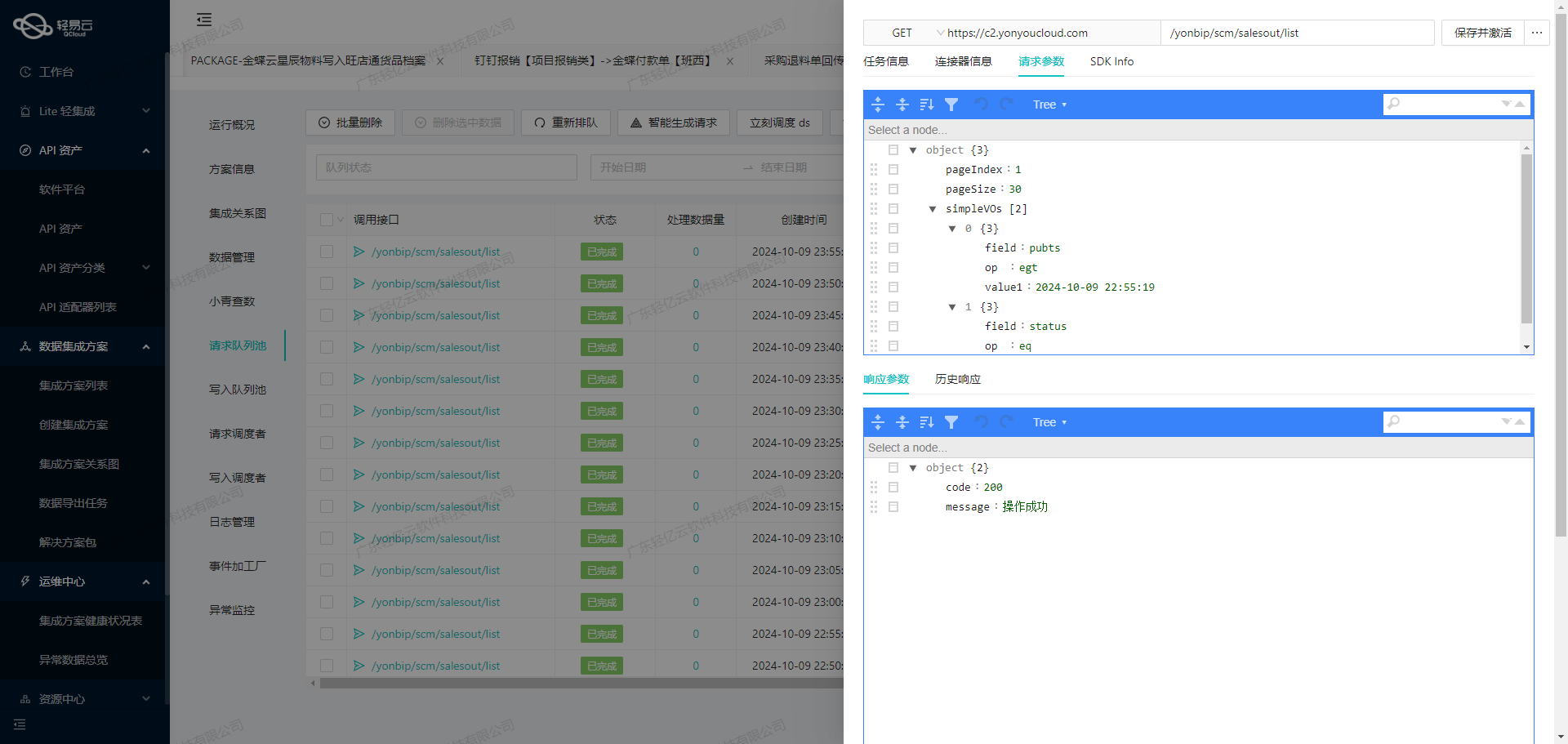
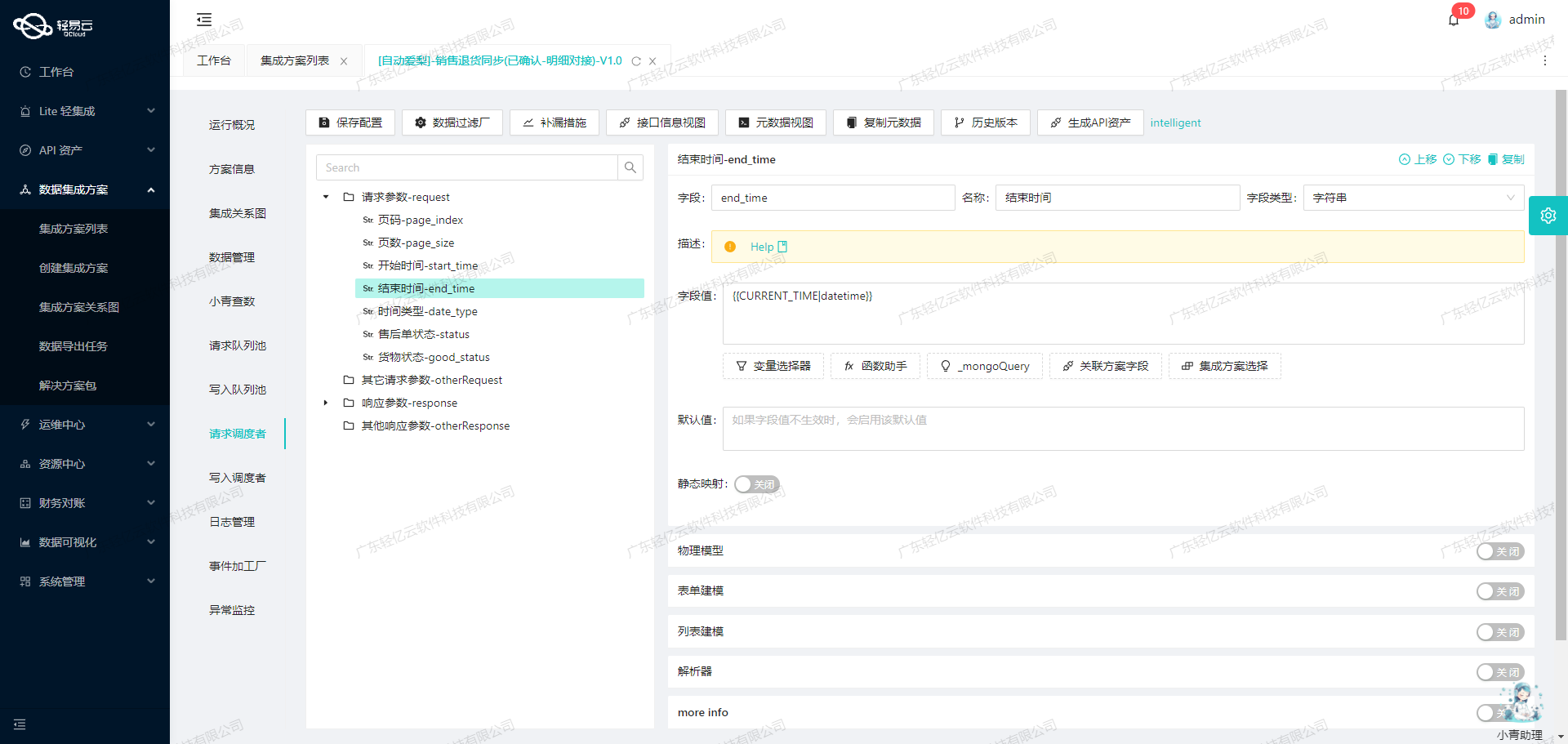
数据转换与写入:从领星ERP到用友U8API的ETL过程
在数据集成的生命周期中,第二步是将已经集成的源平台数据进行ETL(提取、转换、加载)转换,使其符合目标平台用友U8API接口的格式要求,并最终写入目标系统。本文将详细探讨如何实现这一过程,特别是通过轻易云数据集成平台将领星ERP的FBA补货入库数据转换并写入用友U8系统。
数据提取与清洗
首先,我们需要从领星ERP系统中提取所需的数据,这通常通过调用领星ERP的API接口来实现。例如,可以调用/cost/center/api/cost/stream接口来获取FBA补货入库相关的数据。这一步骤需要处理分页和限流问题,以确保数据完整性和系统稳定性。
数据转换
在获取到原始数据后,接下来就是关键的ETL转换步骤。我们需要根据用友U8API接口的格式要求,对数据进行清洗和转换。以下是具体步骤:
-
定义元数据配置: 元数据配置是ETL过程中至关重要的一部分,它定义了如何将源数据字段映射到目标系统所需的字段。以下是一个元数据配置示例:
{ "api": "/apilink/u8api", "effect": "EXECUTE", "method": "POST", "idCheck": true, "operation": { "method": "merge", "field": "wh_name", "bodySum": ["change_quantity"], "bodyName": "goods_list", "header": ["wh_name", "shop_name"], "body": ["sku", "change_quantity"] }, ... } -
字段映射与转换: 根据上述元数据配置,我们需要对领星ERP的数据字段进行映射和转换,使其符合用友U8API接口的要求。例如:
- 日期:直接使用固定值"2024-07-31"。
- 转出部门和转入部门:均为固定值"跨境电商"。
- 出库类别和入库类别:分别为"调拨出库"和"调拨入库"。
- 转出仓库和转入仓库:前者为固定值"国外仓",后者则根据
wh_name字段进行条件转换,如DTECH Multimedia-IN印度仓被映射为DT-IN印度仓。 - 经手人:使用
shop_name字段,并通过mapping机制进行正向映射。 - 单据体(goods_list):包含具体商品信息,如存货编码(SKU)和数量(change_quantity)。
-
自定义逻辑处理: 在某些情况下,需要编写自定义逻辑以适应特定业务需求。例如,在处理仓库名称时,可以使用条件语句来实现动态映射:
CASE '{wh_name}' WHEN 'DTECH Multimedia-IN印度仓' THEN 'DT-IN印度仓' ELSE '{wh_name}' END
数据加载
完成数据转换后,下一步是将处理好的数据通过用友U8API接口写入目标系统。在此过程中,需注意以下几点:
-
高吞吐量支持: 确保平台能够支持高吞吐量的数据写入能力,以便大量数据能够快速被集成到用友U8系统中。
-
异常处理与重试机制: 实现异常处理与错误重试机制,以确保在网络波动或其他异常情况下,数据仍能可靠地写入目标系统。
-
实时监控与日志记录: 通过集中的监控和告警系统,实时跟踪数据集成任务的状态和性能,并记录日志以便于故障排查和性能优化。
总结
通过上述步骤,我们可以有效地将领星ERP中的FBA补货入库数据进行ETL转换,并成功写入用友U8系统。这一过程不仅提高了业务透明度和效率,也确保了数据的一致性和完整性。在实际应用中,通过轻易云平台提供的可视化工具、自定义逻辑处理、实时监控等功能,可以进一步优化这一流程,实现更高效的数据集成。