聚水潭数据集成到MySQL: 案例分享
在复杂的数据处理环境中,如何高效、稳定地实现系统之间的数据对接是一个关键问题。本次案例将聚焦于“聚水潭-其他出入库单-->BI邦盈-其他出入库表”的数据集成方案,实现从聚水潭获取大量业务数据并快速写入到MySQL数据库的全过程。
为了保证大规模数据处理的时效性和准确性,我们使用了支持高吞吐量的数据写入能力,使得大量来自聚水潭系统中的出入库单据能够迅速迁移至MySQL。此外,定时可靠的抓取机制与批量集成功能确保了数据传输过程中的效率和完整性。
首先,在实操过程中,通过调用API /open/other/inout/query 接口,从聚水潭系统中拉取所需的业务数据。这一过程需要特别注意接口分页和限流问题,以避免服务器过载或请求失败。同时,为了应对因网络波动或服务端问题导致的数据遗漏,我们设置了严格的数据质量监控措施以及异常检测机制。一旦检测到异常情况,将立即触发告警并进行错误重试操作。
为适应不同业务需求,我们还自定义了一系列数据转换逻辑,通过轻易云提供的可视化设计工具,对各类复杂源目标映射关系进行直观管理。在此基础上,最终生成符合规范的目标结构,并通过调用MySQL API batchexecute 实现高速批量写入,从而保障性能与正确率。
在实际运行过程中,基于监控和告警功能实时跟踪任务状态,不仅有效掌握整个流程,还能及时定位及解决潜在的问题。从而全方面提升整体运作效率及稳定性。
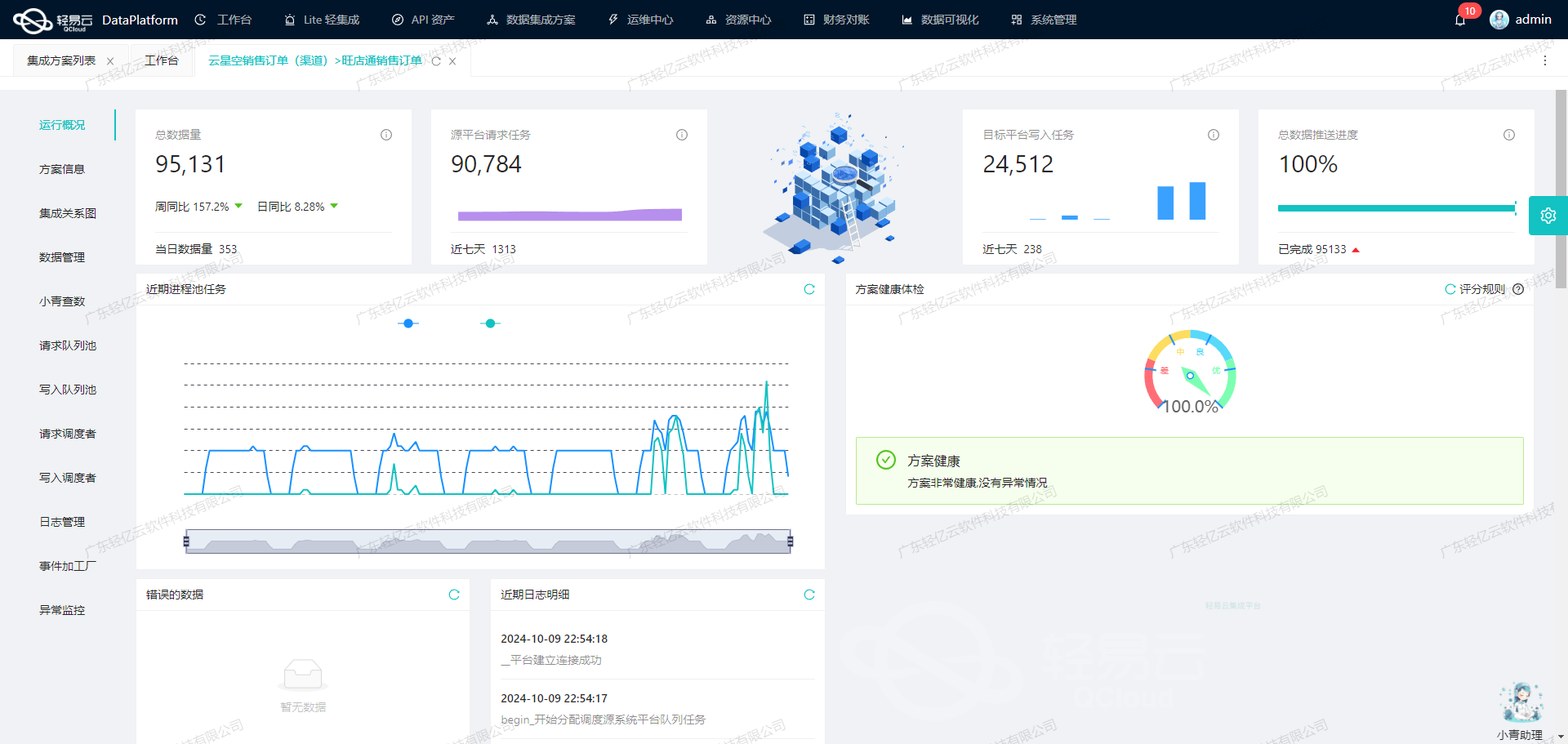
聚水潭接口调用与数据加工:轻易云数据集成平台的第一步
在数据集成过程中,调用源系统接口获取数据是至关重要的一环。本文将深入探讨如何通过轻易云数据集成平台调用聚水潭接口/open/other/inout/query,并对获取的数据进行初步加工。
接口调用配置
首先,我们需要配置元数据以便正确调用聚水潭的接口。以下是具体的元数据配置:
{
"api": "/open/other/inout/query",
"effect": "QUERY",
"method": "POST",
"number": "io_id",
"id": "io_id",
"request": [
{"field":"modified_begin","label":"修改起始时间","type":"datetime","value":"{{LAST_SYNC_TIME|datetime}}"},
{"field":"modified_end","label":"修改结束时间","type":"datetime","value":"{{CURRENT_TIME|datetime}}"},
{"field":"status","label":"单据状态","type":"string","value":"Confirmed"},
{"field":"date_type","label":"时间类型","type":"string","value":"2"},
{"field":"page_index","label":"第几页","type":"string","value":"1"},
{"field":"page_size","label":"每页多少条","type":"string","value":"50"}
],
"autoFillResponse": true,
"condition_bk": [
[{"field": "type", "logic": "in", "value": "其他退货,其他入仓"}]
],
"beatFlat": ["items"],
"delay": 5
}请求参数解析
modified_begin和modified_end:这两个字段用于指定查询的时间范围,分别代表修改起始时间和结束时间。通过使用模板变量{{LAST_SYNC_TIME|datetime}}和{{CURRENT_TIME|datetime}},可以动态地获取上次同步时间和当前时间。status:设置为"Confirmed",表示只查询已确认的单据。date_type:值为"2",表示按照修改时间查询。page_index和page_size:用于分页查询,分别表示当前页码和每页记录数。
数据请求与清洗
在完成接口调用配置后,我们将通过POST请求获取数据。由于聚水潭返回的数据可能包含嵌套结构,因此需要进行初步清洗和展平(flatten)操作。
{
"autoFillResponse": true,
"beatFlat": ["items"]
}上述配置中的autoFillResponse: true表示自动填充响应结果,而beatFlat: ["items"]则指定了需要展平的字段路径。在这个例子中,我们将对返回结果中的"items"字段进行展平处理,以便后续的数据转换和写入操作更加简便。
条件过滤
为了确保只处理特定类型的出入库单据,我们在元数据中添加了条件过滤:
{
"condition_bk": [
[{"field": "type", "logic": "in", "value": "其他退货,其他入仓"}]
]
}此条件过滤器会筛选出类型为“其他退货”和“其他入仓”的单据,从而减少不必要的数据处理负担。
延迟设置
为了避免频繁请求对源系统造成压力,我们可以设置一个延迟:
{
"delay": 5
}该配置表示每次请求之间会有5秒的延迟,从而保证系统稳定性。
实践案例
假设我们需要从聚水潭系统中获取最近一小时内所有已确认的“其他退货”和“其他入仓”单据,并将其集成到BI邦盈系统中。我们可以按照上述元数据配置进行接口调用,并对返回的数据进行清洗、展平和过滤。最终,将处理后的数据写入目标系统,实现无缝对接。
通过以上步骤,我们能够高效地完成轻易云数据集成平台生命周期的第一步——调用源系统接口获取并加工数据。这不仅提升了业务透明度和效率,也为后续的数据转换与写入奠定了坚实基础。
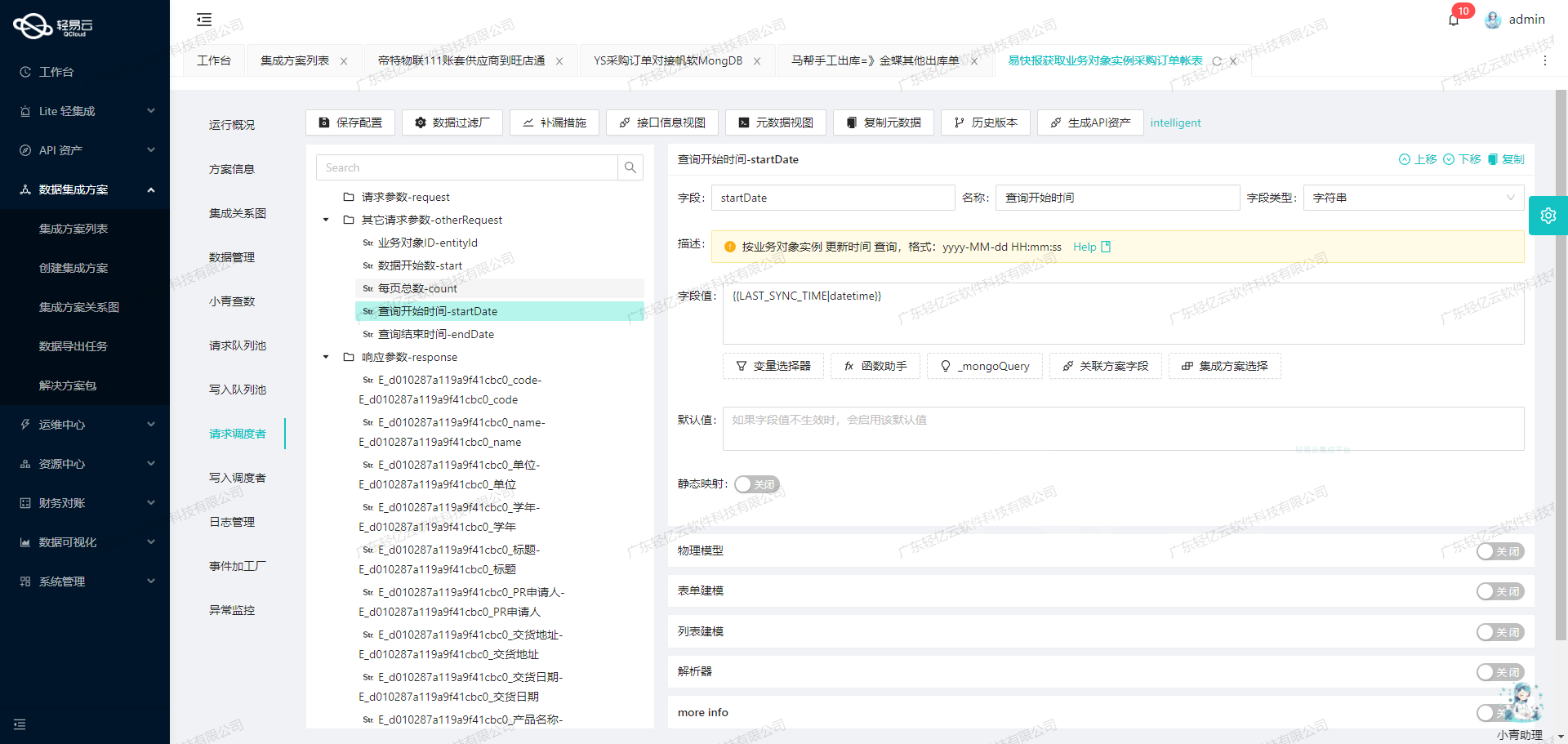
数据集成生命周期中的ETL转换与写入
在数据集成的生命周期中,ETL(提取、转换、加载)是一个至关重要的步骤。本文将详细探讨如何使用轻易云数据集成平台,将已经集成的源平台数据进行ETL转换,转为目标平台 MySQL API 接口所能够接收的格式,并最终写入目标平台。
元数据配置解析
我们以一个具体的元数据配置为例,来说明如何进行 ETL 转换和写入操作。以下是元数据配置:
{
"api": "batchexecute",
"effect": "EXECUTE",
"method": "SQL",
"number": "id",
"id": "id",
"name": "id",
"idCheck": true,
"request": [
{"field":"id","label":"主键","type":"string","value":"{io_id}-{items_ioi_id}"},
{"field":"io_id","label":"出仓单号","type":"string","value":"{io_id}"},
{"field":"io_date","label":"单据日期","type":"string","value":"{io_date}"},
{"field":"status","label":"单据状态","type":"string","value":"{status}"},
{"field":"so_id","label":"线上单号","type":"string","value":"{so_id}"},
{"field":"type","label":"单据类型","type":"string","value":"{type}"},
{"field":"f_status","label":"财务状态","type":"string","value":"{f_status}"},
{"field":"warehouse","label":"仓库名称","type":"string","value":"{warehouse}"},
{"field":"receiver_name","label":"收货人","type":"string","value":"{receiver_name}"},
{"field":"receiver_mobile","label":"收货人手机","type":"string","value":"{receiver_mobile}"},
{"field":"receiver_state","label":"收货人省","type":"string","value":"{receiver_state}"},
{"field":"receiver_city","label":"收货人市","type":"string","value":"{receiver_city}"},
{"field\":\"receiver_district\",\"label\":\"收货人区\",\"type\":\"string\",\"value\":\"{receiver_district}\"},
{\"field\":\"receiver_address\",\"label\":\"收货人地址\",\"type\":\"string\",\"value\":\"{receiver_address}\"},
{\"field\":\"wh_id\",\"label\":\"仓库编号\",\"type\":\"string\",\"value\":\"{wh_id}\"},
{\"field\":\"remark\",\"label\":\"备注\",\"type\":\"string\",\"value\":\"{remark}\"},
{\"field\":\"modified\",\"label\":\"修改时间\",\"type\":\"string\",\"value\":\"{modified}\"},
{\"field\":\"created\",\"label\":\"创建时间\",\"type\":\"string\",\"value\":\"{created}\"},
{\"field\":\"labels\",\"label\":\"多标签\",\"type\":\"string\",\"value\": \" {labels}\"},
{\"field\": \"wms_co_id\", \" label \": \" 分仓编号 \", \" type \": \" string \", \" value \": \" {wms_co_id }\" },
...
...
],
\"otherRequest\":[
{
\" field \ ": \" main_sql \ ", \" label \ ": \" 主语句 \ ", \" type \ ": \" string \ ",
\" describe \ ": \" SQL 首次执行的语句,将会返回:lastInsertId \",
\" value \ ":
"
REPLACE INTO other_inout_query (id, io_id, io_date, status, so_id, type, f_status, warehouse, receiver_name, receiver_mobile, receiver_state, receiver_city, receiver_district, receiver_address, wh_id, remark, modified, created, labels,wms_co_id ,creator_name,wave_id ,drop_co_name,inout_user,l_id ,lc_id ,logistics_company ,lock_wh_id ,lock_wh_name ,items_ioi_id ,items_sku_id ,items_name ,items_unit ,items_properties_value ,items_qty ,items_cost_price ,items_cost_amount ,items_i_id ,items_remark ,items_io_id ,items_sale_price ,items_sale_amount ,items_batch_id ,items_product_date ,items_supplier_id ,items_expiration_date,sns_sku_id,sns_sn) VALUES
"
},
{
\" field \ ": \" limit \ ",
\" label \ ":
"
limit
"
,
...
...
}
]
}数据请求与清洗
首先,我们需要从源平台提取数据。在这个过程中,轻易云的数据集成平台提供了全透明可视化的操作界面,使得数据请求和清洗变得更加直观和高效。
在元数据配置中,每个字段都有其对应的标签、类型和值。例如:
{"field": "id", "label": "主键", "type": "string", "value": "{io_id}-{items_ioi_id}"}表示主键字段由io_id和items_ioi_id拼接而成。{"field": "io_date", "label": "单据日期", "type": "string", "value": "{io_date}"}表示单据日期字段直接取自源数据中的io_date。
这些字段映射关系确保了我们能够准确地从源平台提取到所需的数据。
数据转换与写入
在完成数据请求和清洗之后,我们需要将这些数据转换为目标平台 MySQL API 所能接受的格式,并进行写入操作。
根据元数据配置中的 main_sql 字段,我们可以看到 SQL 插入语句如下:
REPLACE INTO other_inout_query (
id,
io_id,
io_date,
status,
so_id,
type,
f_status,
warehouse,
receiver_name,
receiver_mobile,
receiver_state,
receiver_city,
receiver_district,
receiver_address,
wh_id,
remark,
modified,
created,
labels,
wms_co_id,
...
...
) VALUES这个 SQL 插入语句定义了所有需要插入的数据字段。通过将提取到的数据按照上述字段顺序进行排列,我们可以生成一条完整的 SQL 插入语句。例如:
REPLACE INTO other_inout_query (
id, io_id, io_date,status,...
) VALUES (
'12345-67890', '12345', '2023-10-01', 'completed',...
);批量执行与性能优化
为了提高性能,轻易云的数据集成平台支持批量执行 SQL 操作。通过设置 limit 参数,我们可以控制每次批量处理的数据量。例如:
{"field": "limit", "label": "limit", "type": "string", "value": "1000"}这表示每次批量处理最多处理1000条记录。这种方式不仅提高了效率,还能有效避免因单次处理数据量过大而导致的系统性能问题。
异常处理与监控
在实际操作中,可能会遇到各种异常情况,如网络中断、数据库连接失败等。轻易云的数据集成平台提供了实时监控功能,可以及时发现并处理这些异常情况。例如,通过日志记录和告警机制,可以快速定位问题并采取相应措施。
综上所述,通过合理配置元数据,并利用轻易云的数据集成平台强大的 ETL 功能,我们可以高效地将源平台的数据转换并写入目标 MySQL 平台,实现不同系统间的数据无缝对接。
