案例分享:汤臣倍健营销云数据集成到SQL Server —— 退货入库-广元跃泰
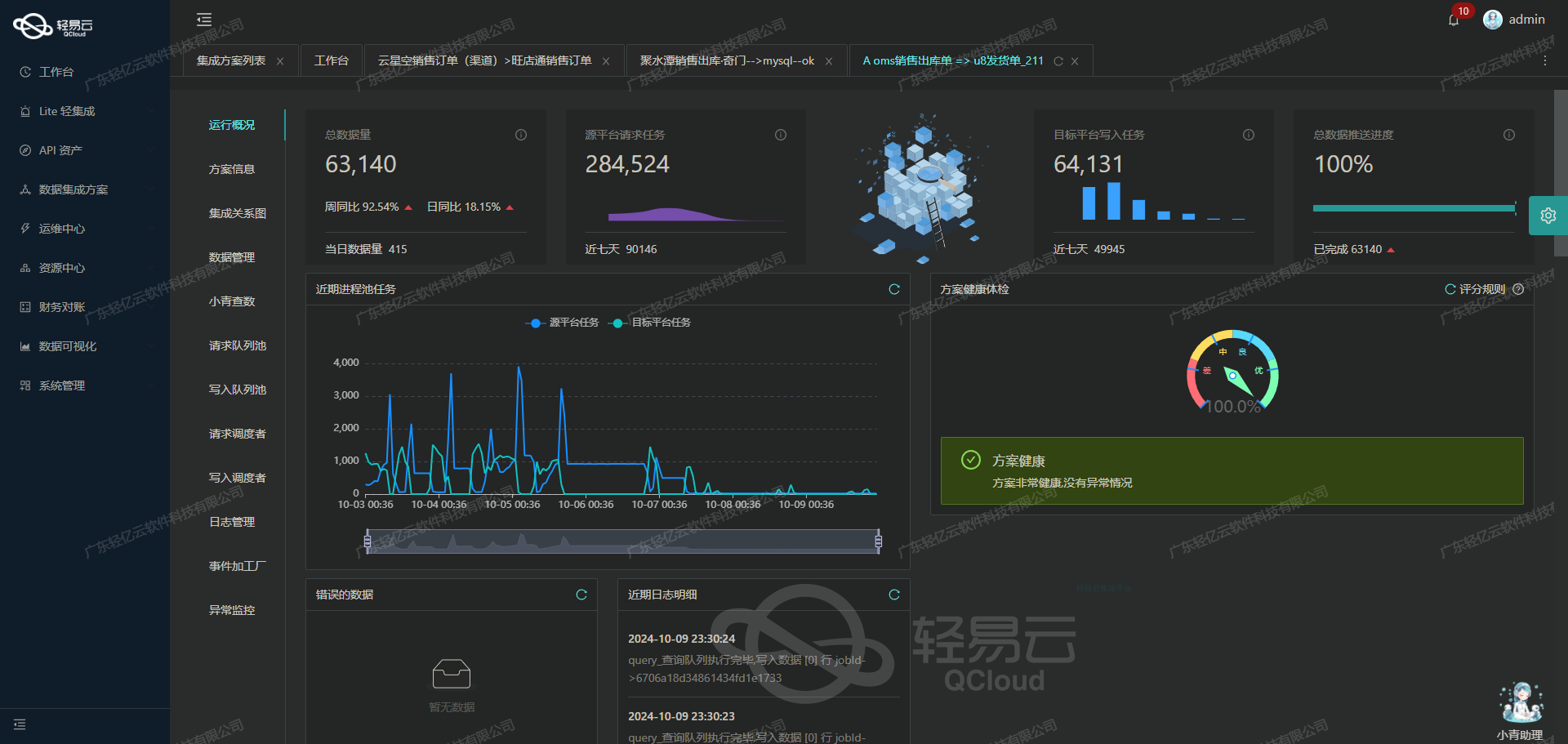
在本案例中,我们探讨了如何将汤臣倍健营销云的数据高效地集成到SQL Server中,以实现退货入库-广元跃泰方案。通过调用/erp/api/order/query/saleReturnOrder接口抓取相关数据,并使用高性能的批量写入技术,将大量的数据准确地导入SQL Server数据库。
首先,为确保从汤臣倍健营销云获取的销售退货订单数据不漏单,我们设计了一套定时触发机制,定期可靠地调用上述API接口,实时监控和记录每个请求与响应状态。此外,通过处理分页和限流问题,使得系统能够稳健运行,即使面对大规模数据也不会出现超时或丢失情况。
为了解决两端系统之间可能存在的数据格式差异问题,在集成过程中,还针对性地对接收自汤臣倍健营销云的数据进行了预处理。特别是在映射字段、日期格式转换等方面进行优化,以保证最终导入 SQL Server 的数据完全符合业务需求并能被正确解析。
当完成初步处理后,大量数据需快速写入 SQL Server 数据库。我们采用了批量插入 (insert) 技术,不仅大幅度提升写入速度,同时保障操作的原子性和一致性。在这过程中,对于任何异常状况如网络断开、权限不足等,我么实现了完善的错误重试机制以及详细的日志记录。这不仅方便后续排查,还能提供全面报告以供分析与改进之用。
通过轻易云平台全透明可视化操作界面,每一步骤都清晰展示,从而极大提高透明度,加快故障排除效率。本方案体现了强大的架构设计,以及精细化运维管理能力,是一个成功实践企业级复杂系统对接的新标杆。
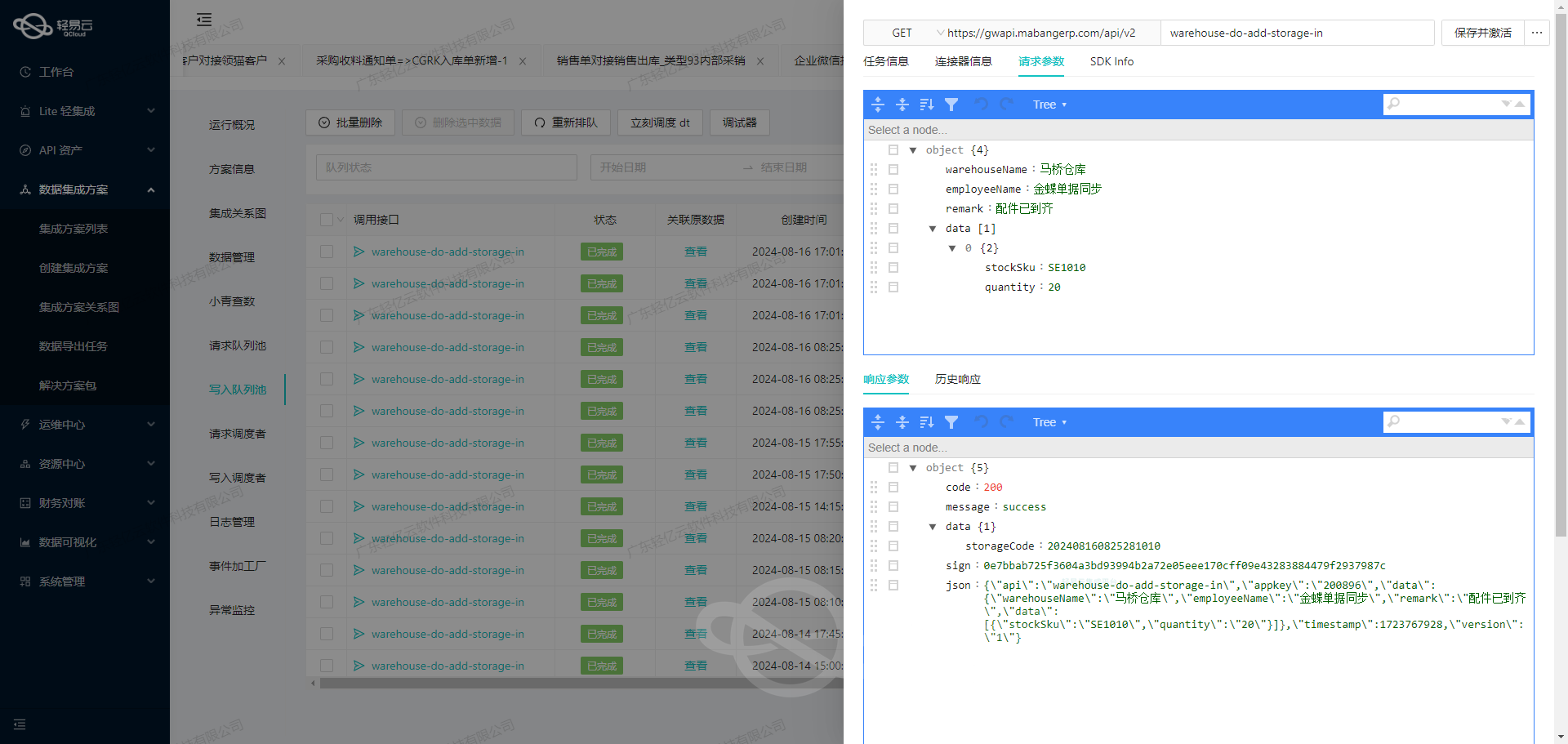
调用源系统汤臣倍健营销云接口获取并加工数据
在数据集成的生命周期中,第一步是从源系统获取数据。本文将深入探讨如何通过调用汤臣倍健营销云的接口/erp/api/order/query/saleReturnOrder来获取退货订单数据,并对其进行初步加工。
接口调用配置
首先,我们需要配置API接口的调用参数。根据元数据配置,接口使用POST方法,以下是主要的请求参数:
tenantId(经销商id):必填项,用于标识经销商。yxyNumber(营销云销售订单号):可选项,传此参数时其他条件无效。number(系统订单号):可选项,传此参数时其他条件无效。status(订单状态):用于筛选订单状态,0表示未审核,1表示已审核(已出库)。beginTime和endTime:用于时间范围查询,格式为0000-00-00或0000-00-00 00:00:00。pageNo和pageSize:用于分页查询,默认值分别为1和30。timeType:时间段标志,0表示创建时间(默认),1表示最后更新时间。
请求示例
以下是一个完整的请求示例:
{
"tenantId": "34cc4109705e4c058b7b3b0352e57d31",
"status": "1",
"beginTime": "{{LAST_SYNC_TIME|datetime}}",
"endTime": "{{CURRENT_TIME|datetime}}",
"pageNo": "1",
"pageSize": "100",
"timeType": "0"
}在这个示例中,我们指定了经销商ID、订单状态、时间范围以及分页信息。注意这里使用了占位符来动态替换同步时间。
数据清洗与转换
获取到原始数据后,需要对其进行清洗和转换,以便后续处理。主要步骤包括:
- 字段映射:将源系统中的字段映射到目标系统所需的字段。例如,将源系统的订单ID映射到目标系统的相应字段。
- 数据过滤:根据业务需求过滤掉不必要的数据。例如,只保留已审核且在指定时间范围内的订单。
- 格式转换:将日期、金额等字段转换为目标系统所需的格式。
示例代码
以下是一个简单的数据清洗与转换示例代码:
import requests
import json
from datetime import datetime
# 配置API请求参数
api_url = "https://example.com/erp/api/order/query/saleReturnOrder"
headers = {"Content-Type": "application/json"}
payload = {
"tenantId": "34cc4109705e4c058b7b3b0352e57d31",
"status": "1",
"beginTime": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"endTime": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
"pageNo": "1",
"pageSize": "100",
"timeType": "0"
}
# 调用API接口获取数据
response = requests.post(api_url, headers=headers, data=json.dumps(payload))
data = response.json()
# 数据清洗与转换
cleaned_data = []
for order in data["orders"]:
cleaned_order = {
"order_id": order["id"],
"order_number": order["number"],
# 添加更多字段映射和转换逻辑
}
cleaned_data.append(cleaned_order)
# 输出清洗后的数据
print(json.dumps(cleaned_data, indent=4))在这个示例中,我们首先配置了API请求参数,然后调用接口获取原始数据。接着,对返回的数据进行清洗和转换,将其整理成目标系统所需的格式。
小结
通过上述步骤,我们成功地从汤臣倍健营销云接口获取了退货订单数据,并对其进行了初步加工。这为后续的数据写入和进一步处理奠定了基础。在实际应用中,可以根据具体业务需求进一步优化和扩展这些操作。
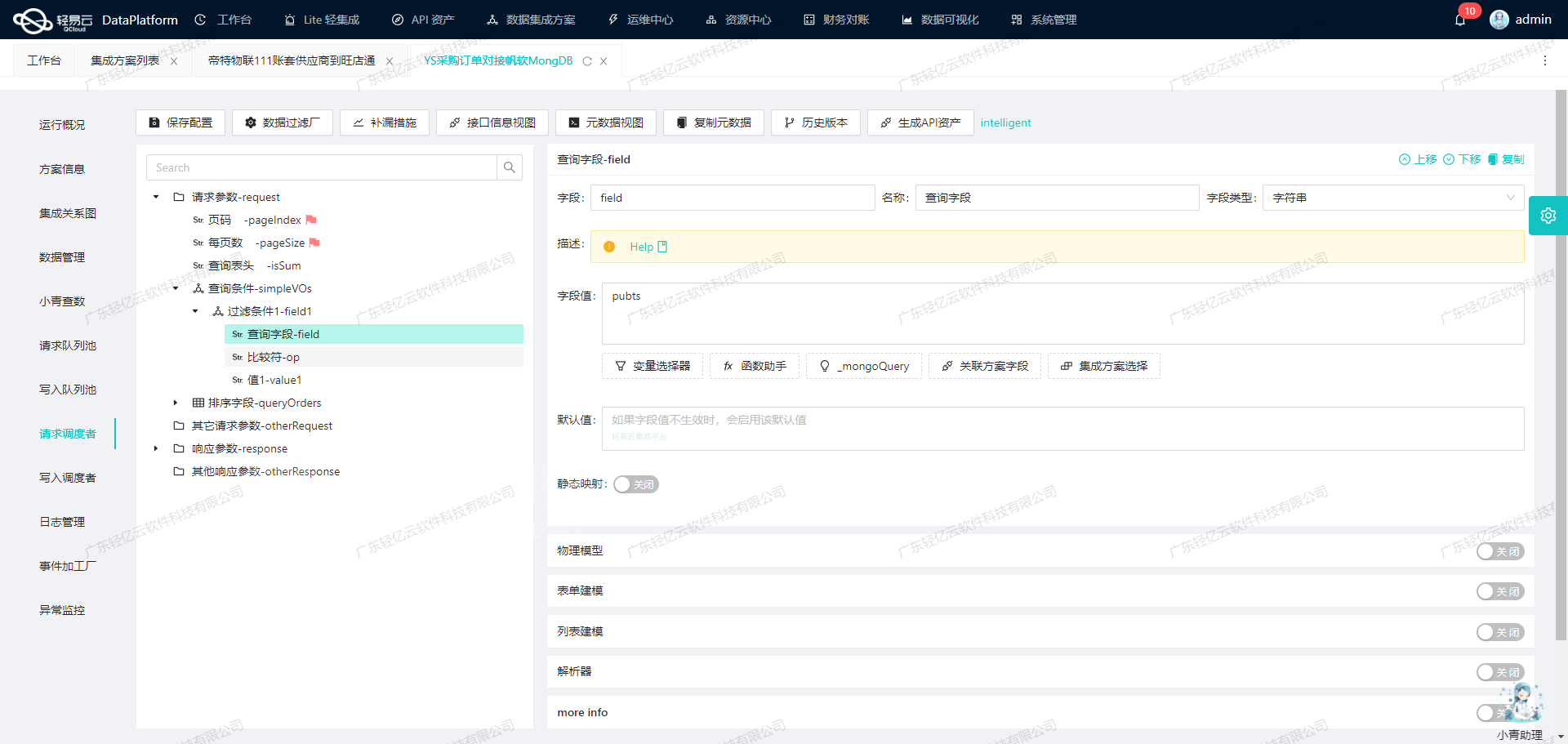
轻易云数据集成平台ETL转换与写入SQL Server API接口
在轻易云数据集成平台的生命周期中,数据转换与写入是关键步骤之一。本文将详细探讨如何将源平台的数据通过ETL(Extract, Transform, Load)过程转换为目标平台SQL Server API接口能够接收的格式,并最终写入目标平台。
元数据配置解析
根据提供的元数据配置,我们需要处理两个主要部分:主表参数和扩展表参数。这些参数将通过POST方法发送至SQL Server API接口。
主表参数配置
主表参数包含以下字段:
- 单号编号(djbh):唯一标识单据的编号。
- 单据类型(djlx):表示单据类型,这里固定为“XHH”。
- 日期(rq):单据审核日期,格式化为字符串。
- 时间(ontime):单据审核时间,格式化为字符串。
- 单位内码(wldwid):客户单位的内码。
- 含税金额(hsje):单据的含税总金额。
- 备注(beizhu):备注信息。
- 原始单号(webdjbh):原始单据编号。
这些字段通过main_params对象进行传递,并在SQL语句中映射到相应的数据库字段。
扩展表参数配置
扩展表参数包含以下字段:
- 单号(djbh):与主表中的单号一致,用于关联主表和扩展表。
- 序号(dj_sn):扩展表中的序号,用于区分不同记录。
- 商品内码(spid):商品的唯一标识,通过查找获取。
- 仓库编号(ckid):商品所在仓库的编号。
- 批号(pihao)、效期(sxrq)、生产日期(baozhiqi):分别表示商品的批次信息、有效期和生产日期。
- 数量(shl)、含税价(hshj)、含税金额(hsje):商品的数量、含税价格和含税总金额。
- 相关单号(xgdjbh)、相关序号(recnum):用于关联原始退货或采购退货等信息。
- 组织ID(hzid)、仓库名称(ckname):组织标识和仓库名称。
这些字段通过extend_params_1数组对象进行传递,并在SQL语句中映射到相应的数据库字段。
数据转换与写入过程
-
数据提取与清洗
- 从源系统提取数据并进行必要的清洗,如去除无效字符、格式化日期时间等。
-
数据转换
- 根据元数据配置,将提取的数据映射到目标格式。例如,将日期格式化为字符串,将金额字段转换为浮点数等。
-
构建请求对象
- 根据元数据中的
request部分,构建POST请求对象。包括主表参数和扩展表参数,确保每个字段都正确映射并赋值。
- 根据元数据中的
-
发送请求
- 使用HTTP POST方法将构建好的请求对象发送至SQL Server API接口。确保请求头和请求体符合API要求。
-
处理响应
- 接收并处理API响应,检查是否有错误发生。如果有错误,根据错误信息进行调试和修正。
示例代码
以下是一个简化示例,展示如何使用Python构建并发送请求:
import requests
import json
from datetime import datetime
# 示例数据
data = {
"number": "123456",
"auditTime": datetime.now(),
"extCusCode": "C001",
"itemList": [
{
"taxlastmoney": 100.0,
"depotNo": "D001",
"_Flot": "BATCH001",
"_Fexp": "2023-12-31",
"_Fmfg": "2023-01-01",
"opernumber": 10,
"taxunitprice": 10.0
}
],
"remark": "Test remark",
"othernumber": "654321"
}
# 构建主表参数
main_params = {
"djbh": data["number"],
"djlx": "XHH",
"rq": data["auditTime"].strftime("%Y-%m-%d"),
"ontime": data["auditTime"].strftime("%H:%M:%S"),
"wldwid": data["extCusCode"],
"hsje": sum(item["taxlastmoney"] for item in data["itemList"]),
"beizhu": data["remark"],
"webdjbh": data["othernumber"]
}
# 构建扩展表参数
extend_params_1 = []
for idx, item in enumerate(data["itemList"], start=1):
extend_params_1.append({
"djbh": data["number"],
"dj_sn": str(idx),
# 假设这里已经通过某种方式查找到spid
"spid": f"SPID{idx}",
"ckid": item["depotNo"],
"pihao": item["_Flot"],
"sxrq": item["_Fexp"],
# 其他字段类似处理...
# ...
})
# 构建最终请求体
request_body = {
"main_params": main_params,
"extend_params_1": extend_params_1
}
# 发送请求
response = requests.post(
url="http://target-sql-server-api/insert",
headers={"Content-Type":"application/json"},
data=json.dumps(request_body)
)
# 检查响应
if response.status_code == 200:
print("Data inserted successfully")
else:
print(f"Error: {response.text}")以上示例展示了如何根据元数据配置构建POST请求,并将其发送至SQL Server API接口。实际应用中,需要根据具体业务逻辑进行调整和优化。