汤臣倍健营销云数据集成到SQL Server的技术案例分享
在企业信息化建设中,数据集成是实现业务流程自动化和优化的重要环节。本文将聚焦于一个具体的系统对接集成案例:如何将汤臣倍健营销云的数据高效、可靠地集成到SQL Server中,以支持“退货入库-广元跃泰”方案的实施。
为了确保数据集成过程的高效性和可靠性,我们采用了轻易云数据集成平台。该平台不仅提供了全生命周期管理,还具备高吞吐量的数据写入能力,使得大量数据能够快速被处理和存储。此外,通过其集中监控和告警系统,我们可以实时跟踪数据集成任务的状态和性能,及时发现并解决潜在问题。
在实际操作中,我们首先调用汤臣倍健营销云提供的API接口/erp/api/order/query/saleReturnOrder来获取退货订单数据。这些数据需要经过自定义的数据转换逻辑,以适应SQL Server的特定业务需求和数据结构。随后,通过SQL Server的写入API insert,我们将处理后的数据批量导入目标数据库。
为了确保整个过程中的数据质量,我们还设置了严格的数据质量监控和异常检测机制。一旦发现任何异常情况,系统会立即触发告警,并启动错误重试机制,以保证最终的数据完整性和准确性。同时,为了解决分页和限流问题,我们设计了一套高效的数据抓取策略,确保每一条记录都能被准确无误地传输到目标平台。
通过这些技术手段,不仅实现了汤臣倍健营销云与SQL Server之间的数据无缝对接,还大幅提升了业务处理效率,为企业带来了显著的价值。在后续章节中,我们将详细探讨每个步骤中的具体实现方法及注意事项。
调用汤臣倍健营销云接口获取并加工数据
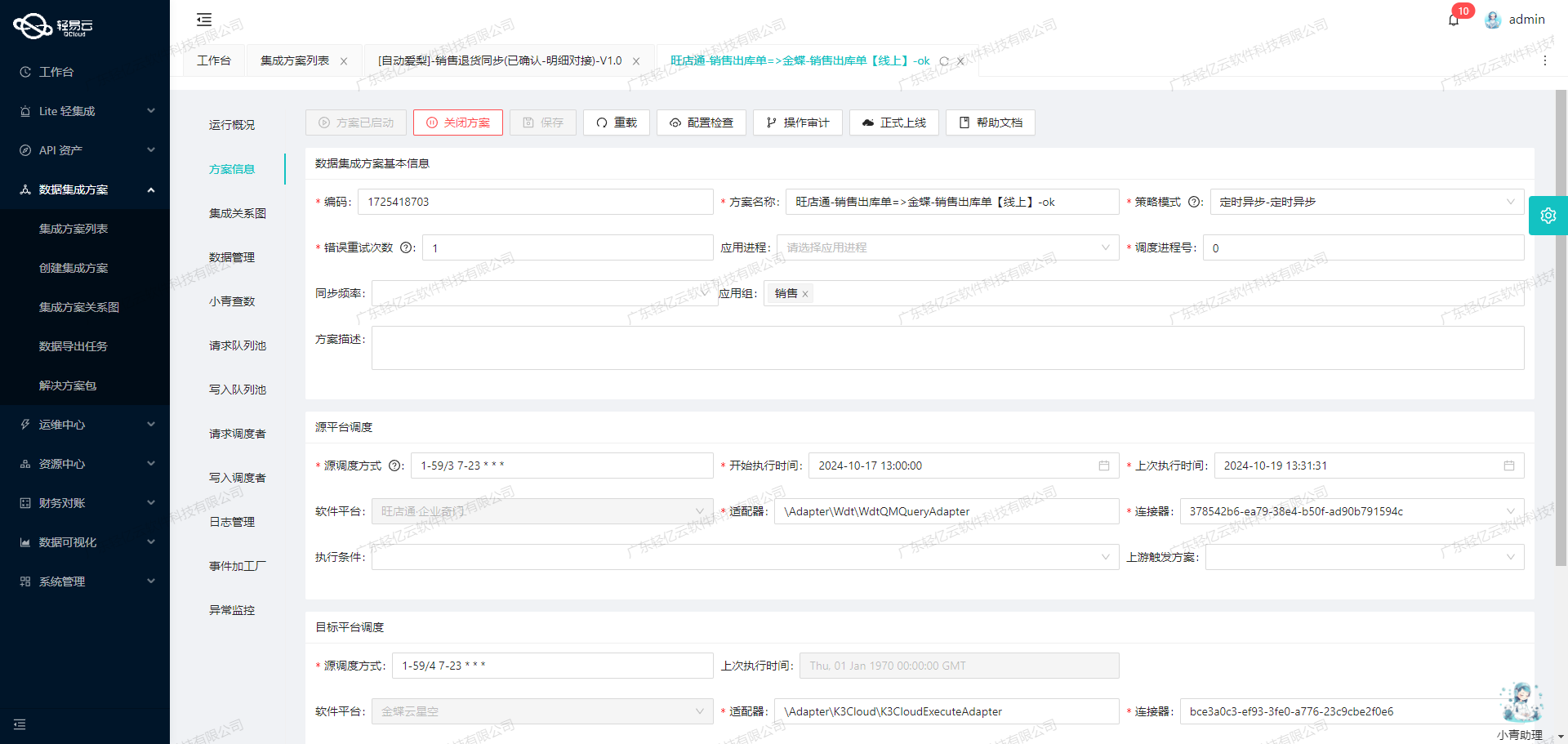
在轻易云数据集成平台的生命周期中,第一步是调用源系统汤臣倍健营销云接口/erp/api/order/query/saleReturnOrder获取退货入库数据,并进行初步加工处理。以下将详细探讨这一过程中的技术细节和实现方法。
接口调用配置
首先,我们需要配置API接口的元数据,以便正确地请求和接收所需的数据。根据提供的元数据配置,接口采用POST方法,主要参数包括:
tenantId: 经销商ID(必填)yxyNumber: 营销云销售订单号number: 系统订单号status: 订单状态(0:未审核, 1:已审核)beginTime和endTime: 时间范围pageNo和pageSize: 分页参数timeType: 查询时间段标识(0:创建时间, 1:最后更新时间)
这些参数确保了我们能够灵活地查询不同条件下的退货入库订单。
数据请求与分页处理
由于可能存在大量的数据,我们需要处理分页问题。每次请求时,通过设置pageNo和pageSize来控制单次返回的数据量。例如,每页返回100条记录,可以通过递增pageNo来逐页获取所有数据。
{
"tenantId": "34cc4109705e4c058b7b3b0352e57d31",
"status": "1",
"beginTime": "{{LAST_SYNC_TIME|datetime}}",
"endTime": "{{CURRENT_TIME|datetime}}",
"pageNo": "1",
"pageSize": "100",
"timeType": "0"
}上述请求示例中,初始页码为1,每页返回100条记录,并基于创建时间进行查询。
数据清洗与转换
在获取到原始数据后,需要对其进行清洗和转换,以适应目标系统SQL Server的需求。这一步骤包括但不限于:
- 字段映射:将汤臣倍健营销云的数据字段映射到SQL Server对应的字段。
- 格式转换:例如,将日期字符串转换为SQL Server支持的日期格式。
- 异常处理:检测并处理异常数据,如缺失值或格式错误。
可以使用轻易云平台提供的自定义数据转换逻辑功能,实现上述操作。例如,将原始JSON中的日期字段从字符串格式转换为标准日期格式:
def convert_date_format(date_str):
from datetime import datetime
return datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S").strftime("%Y-%m-%d")实时监控与日志记录
为了确保整个过程顺利进行,需要实时监控任务状态,并记录相关日志。轻易云平台提供了集中的监控和告警系统,可以实时跟踪每个任务的执行情况。一旦出现异常情况,例如网络超时或API限流问题,可以及时触发告警并采取相应措施。
异常重试机制
在实际操作中,不可避免会遇到网络波动、API限流等问题。为了提高系统稳定性,需要实现异常重试机制。当某次请求失败时,可以按照一定策略重新尝试。例如,采用指数退避算法,在每次重试之间逐渐增加等待时间:
import time
def retry_request(request_func, max_retries=5):
retries = 0
while retries < max_retries:
try:
response = request_func()
if response.status_code == 200:
return response.json()
except Exception as e:
retries += 1
wait_time = 2 ** retries
time.sleep(wait_time)通过以上步骤,我们能够高效地调用汤臣倍健营销云接口,获取并加工退货入库数据,为后续的数据写入和业务分析奠定基础。在整个过程中,充分利用轻易云平台提供的各种特性,如高吞吐量写入能力、实时监控、异常检测等,使得集成过程更加可靠和高效。
退货入库数据集成至SQL Server的ETL转换
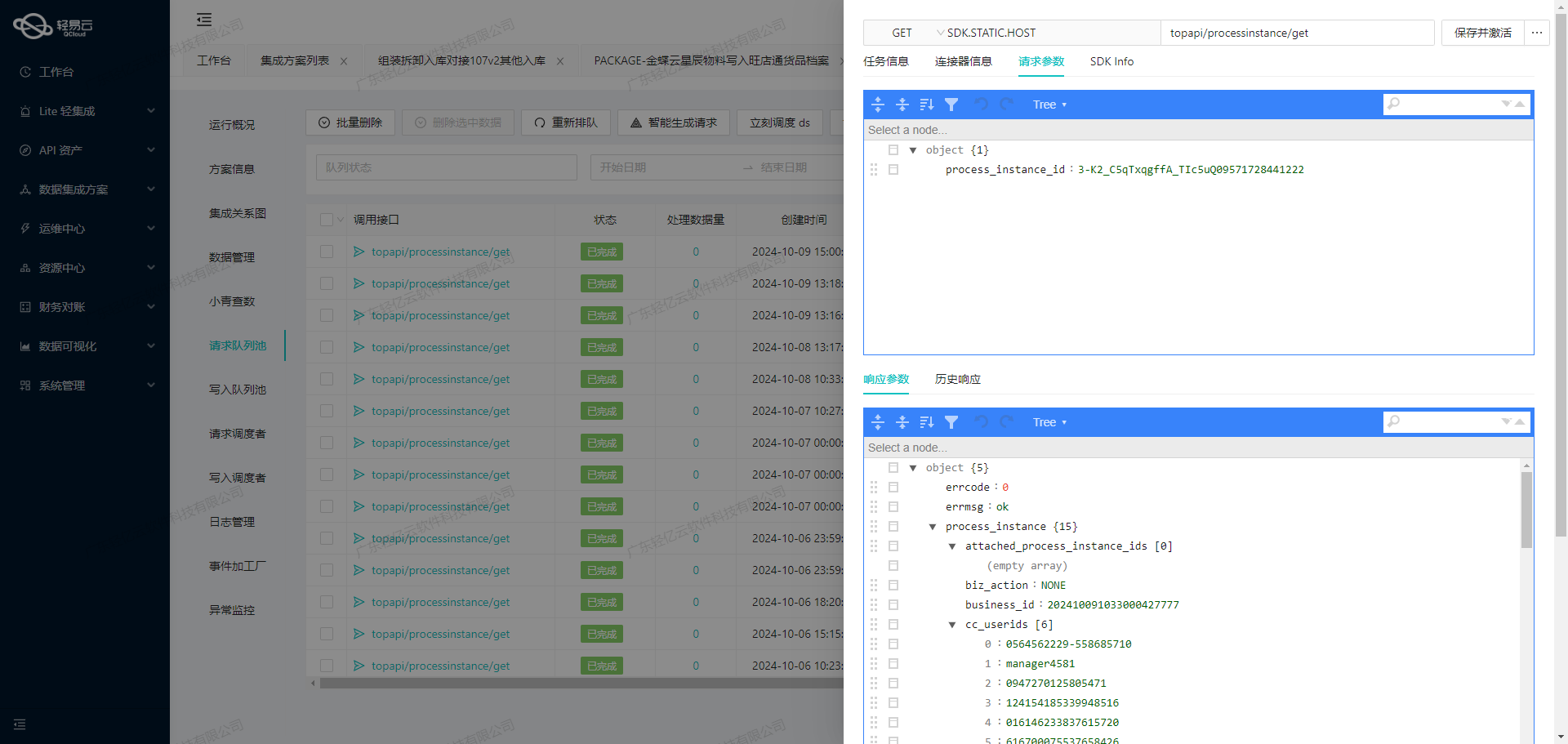
在轻易云数据集成平台的生命周期中,第二步尤为关键,即将已经集成的源平台数据进行ETL(提取、转换、加载)转换,使其符合目标平台SQL Server API接口所能够接收的格式,并最终写入目标平台。以下将详细探讨这一过程。
数据提取与清洗
首先,从源系统中提取原始数据。在本案例中,主要涉及退货入库的数据,这些数据包括主表参数和扩展表参数。提取的数据需要经过清洗,以确保其完整性和准确性。例如,日期格式需要统一,缺失值需要处理等。
数据转换
接下来是数据转换阶段。此阶段的主要任务是将清洗后的数据转化为目标平台SQL Server API接口所能接受的格式。以下是关键步骤:
-
字段映射:根据元数据配置,将源数据字段映射到目标字段。例如,将单号编号
djbh映射到SQL Server中的djbh字段。 -
值转换:对特定字段进行值转换。例如,将日期字段
rq从源系统的格式转换为SQL Server所需的格式。这可以通过自定义逻辑实现,如使用模板字符串{{auditTime|date}}。 -
嵌套结构处理:处理嵌套结构的数据,如扩展表参数中的数组结构,需要逐一展开并映射到对应的SQL Server字段。
数据写入
在完成数据转换后,将其写入目标平台SQL Server。这一步骤涉及调用SQL Server API接口,通过POST方法将转换后的数据发送至API端点。元数据配置中定义了两个主要SQL语句,用于插入主表和扩展表的数据:
-
主SQL语句:
INSERT INTO gxkphz (djbh,djlx,rq,ontime,wldwid,hsje,beizhu,webdjbh) VALUES (:djbh,:djlx,:rq,:ontime,:wldwid,:hsje,:beizhu,:webdjbh) -
扩展SQL语句:
INSERT INTO gxkpmx (djbh,dj_sn,spid,ckid,pihao,sxrq,baozhiqi,shl,hshj,hsje,xgdjbh,recnum,hzid,ckname) VALUES (:djbh,:dj_sn,:spid,:ckid,:pihao,:sxrq,:baozhiqi,:shl,:hshj,:hsje,:xgdjbh,:recnum,:hzid,:ckname)
通过这些预定义的SQL语句,可以高效地将转换后的数据插入到相应的数据库表中。
异常处理与重试机制
在整个ETL过程中,可能会遇到各种异常情况,如网络延迟、API调用失败等。因此,必须实现异常处理与重试机制,以确保数据能够可靠地写入SQL Server。具体措施包括:
- 捕获异常:在每次API调用时捕获可能出现的异常。
- 重试策略:设置重试次数和间隔时间,在遇到临时性错误时自动重试。
- 日志记录:记录每次操作的日志,包括成功和失败的信息,以便后续分析和排查问题。
实时监控与告警
为了确保整个ETL过程的顺利进行,需要实时监控任务状态和性能,并设置告警系统。当出现异常情况时,及时发出告警通知相关人员进行处理。这可以通过轻易云提供的集中监控和告警系统实现。
数据质量监控
最后,为了保证写入SQL Server的数据质量,需要进行持续的数据质量监控。通过轻易云的数据质量监控功能,可以及时发现并处理数据中的问题,例如重复记录、缺失值等。
总之,通过上述步骤,可以高效地将退货入库的数据从源平台转化并写入目标平台SQL Server,实现不同系统间的数据无缝对接。