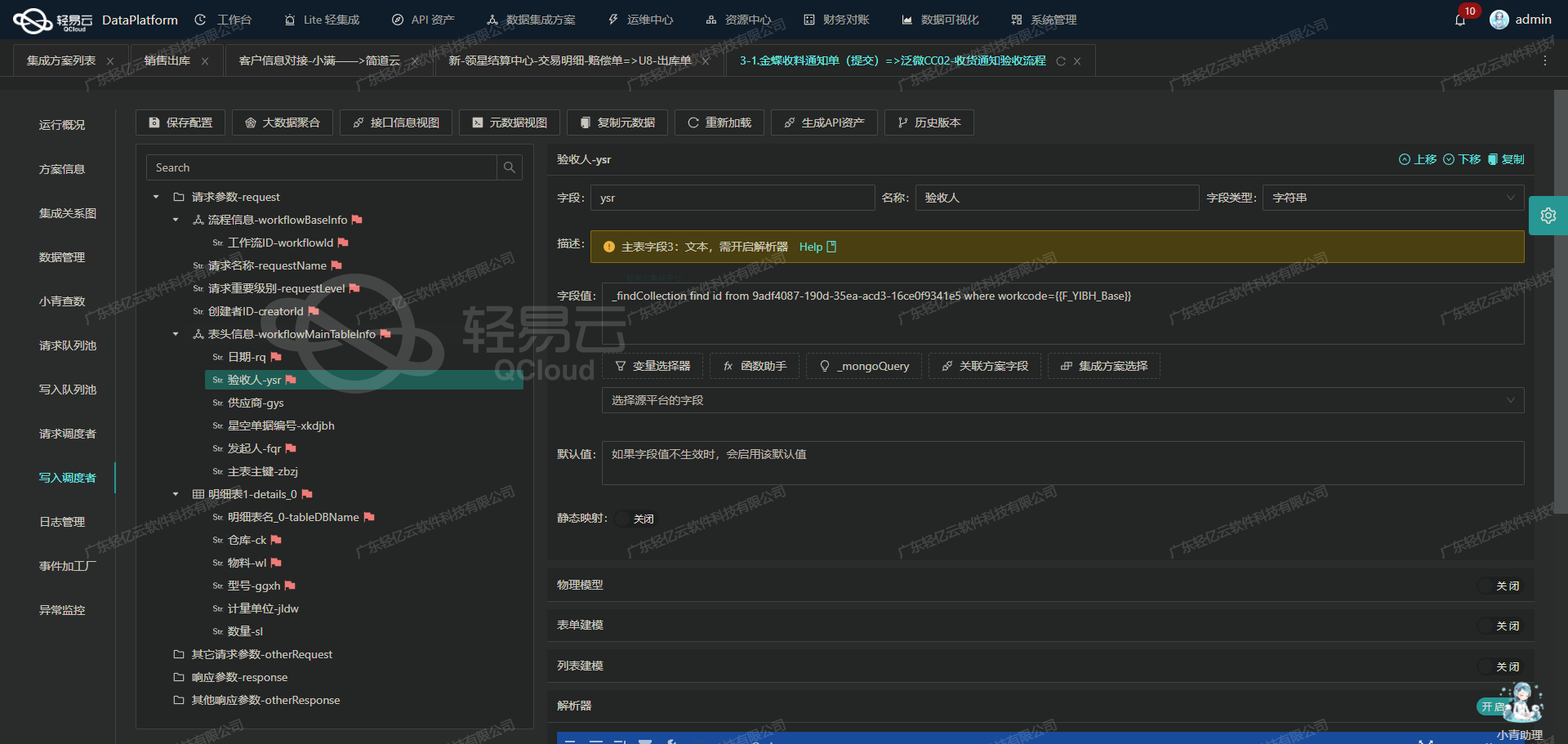
金蝶云星空数据集成到钉钉的案例分享:传给金蝶后,回传钉钉提示(已审核)
在数据驱动业务决策的环境中,如何高效、可靠地实现不同系统间的数据对接成为了企业关注的焦点。本文将深入探讨一个实际运行的方案,通过轻易云数据集成平台,将金蝶云星空中的业务数据无缝整合到钉钉,并实现自动化通知流程。
数据获取与处理
首先,需要调用金蝶云星空提供的executeBillQuery API接口来抓取所需的数据。在实施过程中,我们采用定时任务方式,每日定时从金蝶云星空中拉取最新审核通过的订单数据。面对大规模的数据量,我们还特别注意到了分页和限流问题,通过实现细致入微的数据分页机制,有效避免了API请求超出限制,以及确保每个订单都不被遗漏。
// 示例代码片段:调用executeBillQuery接口
Map<String, String> params = new HashMap<>();
params.put("billType", "ORDER");
params.put("status", "AUDITED");
// 其他必要参数设置...
String response = HttpRequest.post(k3cloudUrl + "/ExecuteBillQuery")
.header("Content-Type", "application/json")
.body(new JSONObject(params).toString())
.execute().body();数据格式转换与映射
由于金蝶和钉钉之间存在较大的数据格式差异,在导入前必须进行详细的数据清洗与映射。例如,从金蝶获取到包含多个字段的信息,我们需要按照预定义好的规则,重新整理成符合钉钉要求的数据结构。这一步不仅仅是简单字段匹配,还涉及复杂的业务逻辑判断,以保证所有信息准确无误地转移至目标系统。
// 示例代码片段:格式转换与映射
List<Map<String, Object>> k3DataList = parseK3Response(response);
List<DingTalkDataFormat> dingtalkDataList = new ArrayList<>();
for (Map<String, Object> entry : k3DataList) {
DingTalkDataFormat data = new DingTalkDataFormat();
data.setTitle(entry.get("OrderName").toString());
data.setDetail(entry.get("OrderDetail").toString());
// 其他字段映射...
dingtalkDataList.add(data);
}批量写入与异常处理
为了提高效率,转换后的批量数据直接使用topapi/process/instance/comment/add API接口写入到钉矩阵内,同时我们针对可能出现的问题设计了完善的异常重试机制。具体而言,当一次调用失败时,会记录错误日志并触发重试操作,以
调用金蝶云星空接口executeBillQuery获取并加工数据
在数据集成的生命周期中,调用源系统接口获取数据是至关重要的一步。本文将详细探讨如何通过轻易云数据集成平台调用金蝶云星空的executeBillQuery接口,并对获取的数据进行初步加工。
接口调用配置
首先,我们需要根据元数据配置来设置接口调用参数。以下是关键的配置项:
- API:
executeBillQuery - Method:
POST - FormId:
AP_PAYBILL - FieldKeys: 包含所有需要查询的字段key集合
- FilterString: 过滤条件,用于筛选符合条件的数据
- Pagination: 分页参数,确保每次请求的数据量可控
请求参数构建
根据元数据配置,我们需要构建请求参数。以下是一个示例请求体:
{
"FormId": "AP_PAYBILL",
"FieldKeys": "FPAYBILLENTRY_FEntryID,FID,FBillNo,FDOCUMENTSTATUS,FCreatorId,FAPPROVERID,FCreateDate,FSETTLEORGID.FNumber,FApproveDate,FPURCHASEORGID.FNumber,FPAYTOTALAMOUNTFOR_H,FCURRENCYID.FNumber,FDATE,FModifyDate,FModifierId,FWRITTENOFFSTATUS,FBillTypeID.FNumber,FPURCHASERID.FNumber,FPURCHASERGROUPID,FPURCHASEDEPTID.FNumber,FREALPAYAMOUNTFOR_H,FACCOUNTSYSTEM,FCancellerId,FCancelStatus,FCancelDate,FCONTACTUNITTYPE,FCONTACTUNIT.FNumber,FRECTUNITTYPE,FRECTUNIT.FNumber,FSOURCESYSTEM,FBUSINESSTYPE,FISINIT,FDepartment.FNumber,FPAYORGID.FNumber,FISSAMEORG,FIsCredit,FSETTLERATE,FPAYAMOUNTFOR,FEXCHANGETYPE,FMAINBOOKID,FSETTLECUR,FPAYTOTALAMOUNT_H,FPAYAMOUNT,FREALPAYAMOUNT_H,FEXCHANGERATE",
"FilterString": "FApproveDate>='2023-01-01' and FDOCUMENTSTATUS='C'",
"Limit": 500,
"StartRow": 0,
"TopRowCount": true
}在这个请求体中,FieldKeys包含了所有需要查询的字段,FilterString用于筛选出审核状态为“已审核”的单据,分页参数Limit和StartRow控制每次请求的数据量。
数据处理与清洗
一旦成功获取到数据,我们需要对其进行初步加工和清洗。以下是一些常见的处理步骤:
- 字段映射与转换:将金蝶返回的数据字段映射到目标系统所需的字段格式。例如,将金蝶的日期格式转换为目标系统所需的标准日期格式。
- 数据过滤:进一步过滤不符合业务需求的数据。例如,只保留特定付款组织(如8.01、8.03等)的记录。
- 异常处理:处理可能出现的数据异常,如缺失值、重复值等。
以下是一个简单的数据处理示例:
def process_data(raw_data):
processed_data = []
for record in raw_data:
if record['FPAYORGID'] in ['8.01', '8.03', '8.04', '8.06', '8.07', '8.08']:
processed_record = {
'单据编号': record['FBillNo'],
'创建日期': format_date(record['FCreateDate']),
'审核日期': format_date(record['FApproveDate']),
'付款组织': record['FPAYORGID'],
'应付金额': float(record['FPAYTOTALAMOUNTFOR_H']),
# 添加更多字段转换...
}
processed_data.append(processed_record)
return processed_data
def format_date(date_str):
# 假设原始日期格式为 YYYY-MM-DD HH:MM:SS
return date_str.split(' ')[0]异常处理与日志记录
在实际操作中,接口调用和数据处理过程中可能会遇到各种异常情况,如网络超时、数据格式错误等。我们需要对这些异常进行捕获和处理,并记录日志以便后续分析和排查。
import logging
logging.basicConfig(level=logging.INFO)
def fetch_and_process_data():
try:
response = call_executeBillQuery_api()
if response.status_code == 200:
raw_data = response.json()
processed_data = process_data(raw_data)
logging.info(f"Successfully processed {len(processed_data)} records.")
else:
logging.error(f"API call failed with status code {response.status_code}")
except Exception as e:
logging.error(f"An error occurred: {str(e)}")
fetch_and_process_data()通过上述步骤,我们可以高效地从金蝶云星空获取并加工所需的数据,为后续的数据转换与写入奠定基础。
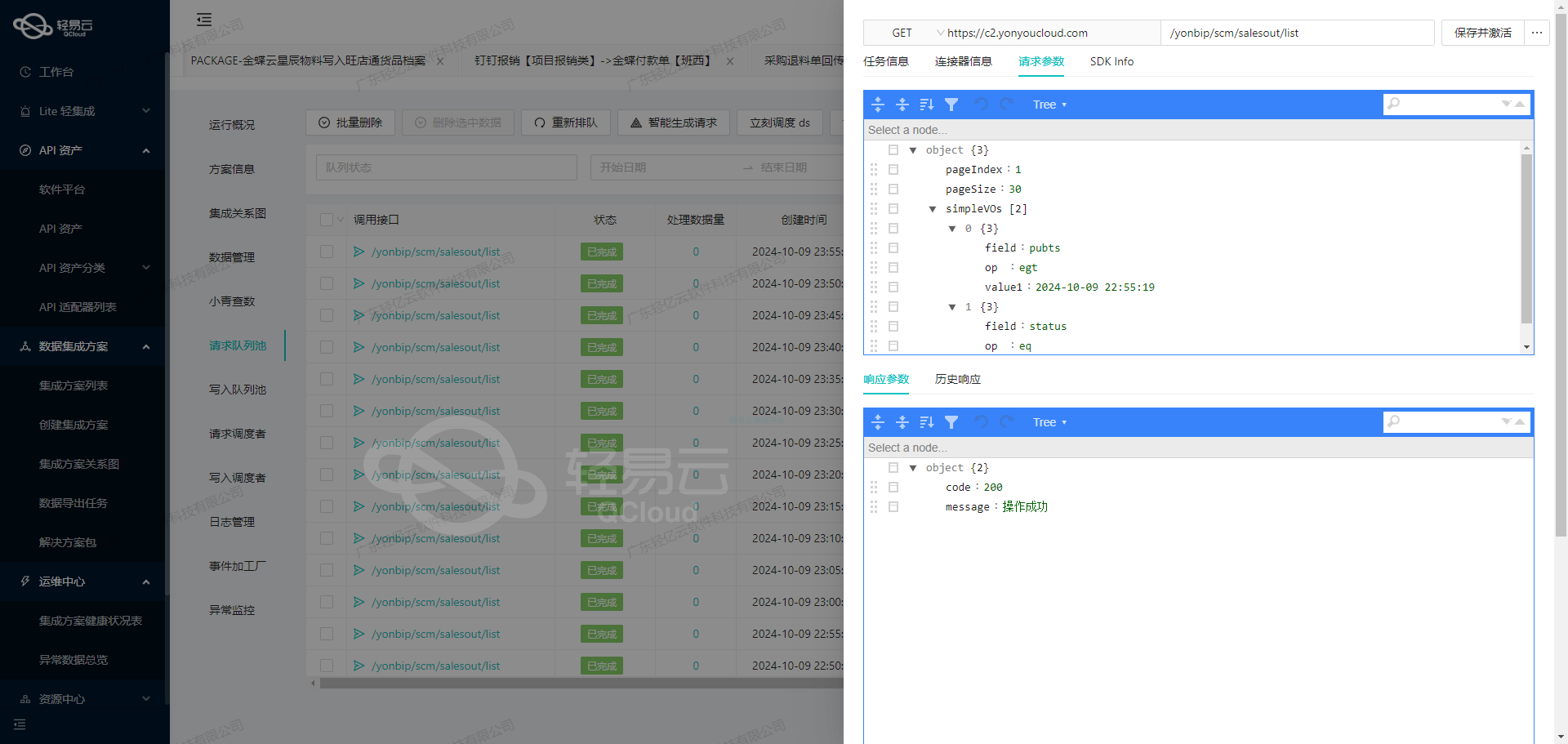
数据集成生命周期中的ETL转换:将源平台数据转为钉钉API接口格式
在轻易云数据集成平台的全生命周期管理中,数据的ETL(Extract, Transform, Load)转换是关键环节之一。本文将详细探讨如何将已集成的源平台数据通过ETL转换,转为钉钉API接口所能接收的格式,并最终写入目标平台。
API接口元数据配置解析
首先,了解目标平台(钉钉)的API接口元数据配置是至关重要的。以下是我们要使用的API接口元数据配置:
{
"api": "topapi/process/instance/comment/add",
"method": "POST",
"idCheck": true,
"request": [
{
"field": "request",
"label": "请求对象",
"type": "object",
"children": [
{
"field": "process_instance_id",
"label": "审批实例ID",
"type": "string",
"describe": "可通过调用获取审批实例ID列表接口获取。",
"value": "_findCollection find id from 950d161e-e92d-3d49-9d70-342c1503f694 where business_id={FBillNo}",
"parent": "request"
},
{
"field": "text",
"label": "评论的内容",
"type": "string",
"value": "已审核",
"parent": "request"
},
{
"field": "comment_userid",
"label": "评论人的userid",
"type": "string",
"value": "112018120420563028",
"parent": "request"
}
]
}
]
}数据提取与清洗
在ETL过程中,首先需要从源平台提取数据并进行清洗。假设我们从金蝶系统中提取了相关审批信息,其中包括业务编号(FBillNo)。这一步骤确保了数据的一致性和准确性,为后续的转换打下基础。
数据转换
接下来,我们需要将提取的数据转换为钉钉API接口所需的格式。根据元数据配置,我们需要构建一个包含process_instance_id、text和comment_userid字段的请求对象。
-
审批实例ID:通过调用获取审批实例ID列表接口,使用业务编号(FBillNo)来查找对应的审批实例ID。
{ "_findCollection find id from 950d161e-e92d-3d49-9d70-342c1503f694 where business_id={FBillNo}" } -
评论内容:固定值“已审核”。
{ “text”: “已审核” } -
评论人用户ID:固定值“112018120420563028”。
{ “comment_userid”: “112018120420563028” }
组合以上字段,我们可以构建出完整的请求对象:
{
“request”: {
“process_instance_id”: “_findCollection find id from 950d161e-e92d-3d49-9d70-342c1503f694 where business_id={FBillNo}”,
“text”: “已审核”,
“comment_userid”: “112018120420563028”
}
}数据写入
最后一步是将转换后的数据通过POST方法写入钉钉API接口。根据元数据配置,目标API为topapi/process/instance/comment/add。
在实际操作中,可以使用HTTP客户端库(如Python中的requests库)来实现这一过程:
import requests
url = 'https://oapi.dingtalk.com/topapi/process/instance/comment/add'
headers = {'Content-Type': 'application/json'}
data = {
'request': {
'process_instance_id': '_findCollection find id from 950d161e-e92d-3d49-9d70-342c1503f694 where business_id={FBillNo}',
'text': '已审核',
'comment_userid': '112018120420563028'
}
}
response = requests.post(url, json=data, headers=headers)
if response.status_code == 200:
print('Data successfully written to DingTalk API')
else:
print('Failed to write data to DingTalk API')通过上述步骤,我们完成了从源平台到目标平台的数据ETL转换与写入。这一过程不仅确保了数据的一致性和准确性,还极大提升了业务流程的自动化程度和效率。