聚水潭调拨对接金蝶直接调拨ok案例分享
在企业系统集成的过程中,数据的高效流动和无缝对接是至关重要的。本文将聚焦于如何通过轻易云数据集成平台,实现聚水潭与金蝶云星空之间的数据对接。本次方案名为“聚水潭调拨对接金蝶直接调拨ok”,旨在提供一个高效、可靠的数据集成解决方案。
技术背景及挑战
实现一个成功的数据集成,需要解决诸多技术难题,例如确保大量数据能够快速、高吞吐量地写入到目标系统中,以保障业务时效性。此外,还需要合理处理API接口的分页和限流问题,以及不同数据格式间的转换与映射问题。特别是在面对像聚水潭这样的复杂业务场景时,更需要实时监控与异常处理机制来保证数据完整性,不漏单。
关键技术要点
-
API 接口调用:
- 从聚水潭获取数据使用
allocate.queryAPI。 - 将获取到的数据批量写入金蝶云星空使用
batchSaveAPI。
调用频率和每次请求的数据量均需控制好,以避免触发限流机制。同时,通过编写自定义转换逻辑来适配两边平台不一致的数据结构。
- 从聚水潭获取数据使用
-
数据质量监控: 在整个流程中,启用集中化的监控和告警系统,不仅可以实时跟踪任务状态,还能及时发现并处理潜在的问题。这一功能有助于确保所有操作都透明且可追溯,提高整体管理效率。
-
高吞吐量支持: 本案中特别强调了支持大批量数据快速写入能力,确保从聚水潭导出的海量订单信息,能够以极低延迟传递至金蝶云星空,从而提升供应链管理效率。
-
异常检测与重试机制: 集成过程中的任何异常,如网络波动或接口响应超时,都需要被准确捕获并记录,并自动触发错误重试机制。这不仅减少了人为干预,也大幅提升了系统稳定性。
-
定制化映射规则设计: 对于源端(聚水潭)和目的端(金蝶云星空)的字段差异,通过灵活配置定制化映射规则,使得各种复杂转换需求都能得到满足。例如,针对特定类型订单设置专门的信息映射逻辑,从而保证业务逻辑的一致性。
本文将具体展示如何通过以上关键步骤,将企业内部多个独立但相互关联的信息孤岛有效连接起来,为读者呈现一个完备、实用且具有
调用聚水潭接口allocate.query获取并加工数据的技术案例
在数据集成生命周期的第一步中,调用源系统接口以获取原始数据是至关重要的。本文将深入探讨如何通过轻易云数据集成平台调用聚水潭的allocate.query接口,并对获取的数据进行初步加工。
API接口调用配置
在轻易云数据集成平台中,我们需要配置元数据以便正确调用聚水潭的allocate.query接口。以下是具体的元数据配置:
{
"api": "allocate.query",
"method": "POST",
"number": "io_id",
"id": "io_id",
"pagination": {
"pageSize": 50
},
"condition": [
[
{"field": "status", "logic": "eq", "value": "Confirmed"},
{"field": "type", "logic": "eq", "value": "调拨入"}
]
],
"idCheck": true,
"request": [
{"field": "modified_begin", "label": "修改开始时间",
"type": "string",
"describe": "修改起始时间,和结束时间必须同时存在,时间间隔不能超过七天,与线上单号不能同时为空",
"value":"{{LAST_SYNC_TIME|datetime}}"
},
{"field": "modified_end",
"label": "修改结束时间",
"type":"string",
"describe":"修改结束时间,和起始时间必须同时存在,时间间隔不能超过七天,与线上单号不能同时为空",
"value":"{{CURRENT_TIME|datetime}}"
},
{"field":"so_ids",
"label":"线上单号",
"type":"string",
"describe":"指定线上订单号,和时间段不能同时为空"
},
{"field":"page_index",
"label":"开始页码",
"type":"string",
"describe":"第几页,从第一页开始,默认1",
"value":"1"
},
{"field":"page_size",
"label":"每页条数",
*type*:"string",
*describe*:"每页多少条,默认30,最大50",
*value*:"{PAGINATION_PAGE_SIZE}"
}
]
}数据请求与清洗
在配置好元数据后,我们通过POST方法向allocate.query接口发送请求。请求参数包括:
modified_begin和modified_end: 用于指定查询的时间范围。这两个字段必须同时存在且间隔不超过七天。so_ids: 指定线上订单号,与时间段不能同时为空。page_index: 查询的起始页码,默认为1。page_size: 每页返回的数据条数,最大为50。
这些参数确保我们能够精准地获取到所需的数据,并且可以分页处理大批量的数据。
数据转换与写入
获取到原始数据后,需要对其进行清洗和转换,以便后续写入目标系统。以下是一个简单的数据清洗和转换示例:
import json
import requests
from datetime import datetime, timedelta
# 配置请求参数
params = {
'modified_begin': (datetime.now() - timedelta(days=7)).strftime('%Y-%m-%d %H:%M:%S'),
'modified_end': datetime.now().strftime('%Y-%m-%d %H:%M:%S'),
'page_index': 1,
'page_size': 50,
}
# 发起POST请求
response = requests.post('https://api.jushuitan.com/allocate.query', data=json.dumps(params))
data = response.json()
# 数据清洗与转换
cleaned_data = []
for item in data['items']:
cleaned_item = {
'io_id': item['io_id'],
'status': item['status'],
'type': item['type'],
'modified_time': item['modified_time'],
# 添加其他需要的字段
}
cleaned_data.append(cleaned_item)
# 将清洗后的数据写入目标系统(例如金蝶)
# write_to_target_system(cleaned_data)在上述代码中,我们首先配置了查询参数,然后通过POST请求获取原始数据。接着,对返回的数据进行遍历和清洗,将所需字段提取出来并存储在新的列表中。最后,可以将清洗后的数据写入目标系统,如金蝶。
注意事项
- 分页处理:由于每次请求最多只能返回50条记录,因此需要实现分页逻辑来处理大批量数据。
- 错误处理:确保对API请求失败或返回错误信息时进行适当处理,以保证系统稳定性。
- 性能优化:根据实际需求调整分页大小和查询频率,以优化性能。
通过以上步骤,我们可以高效地调用聚水潭接口获取并加工数据,为后续的数据转换与写入打下坚实基础。
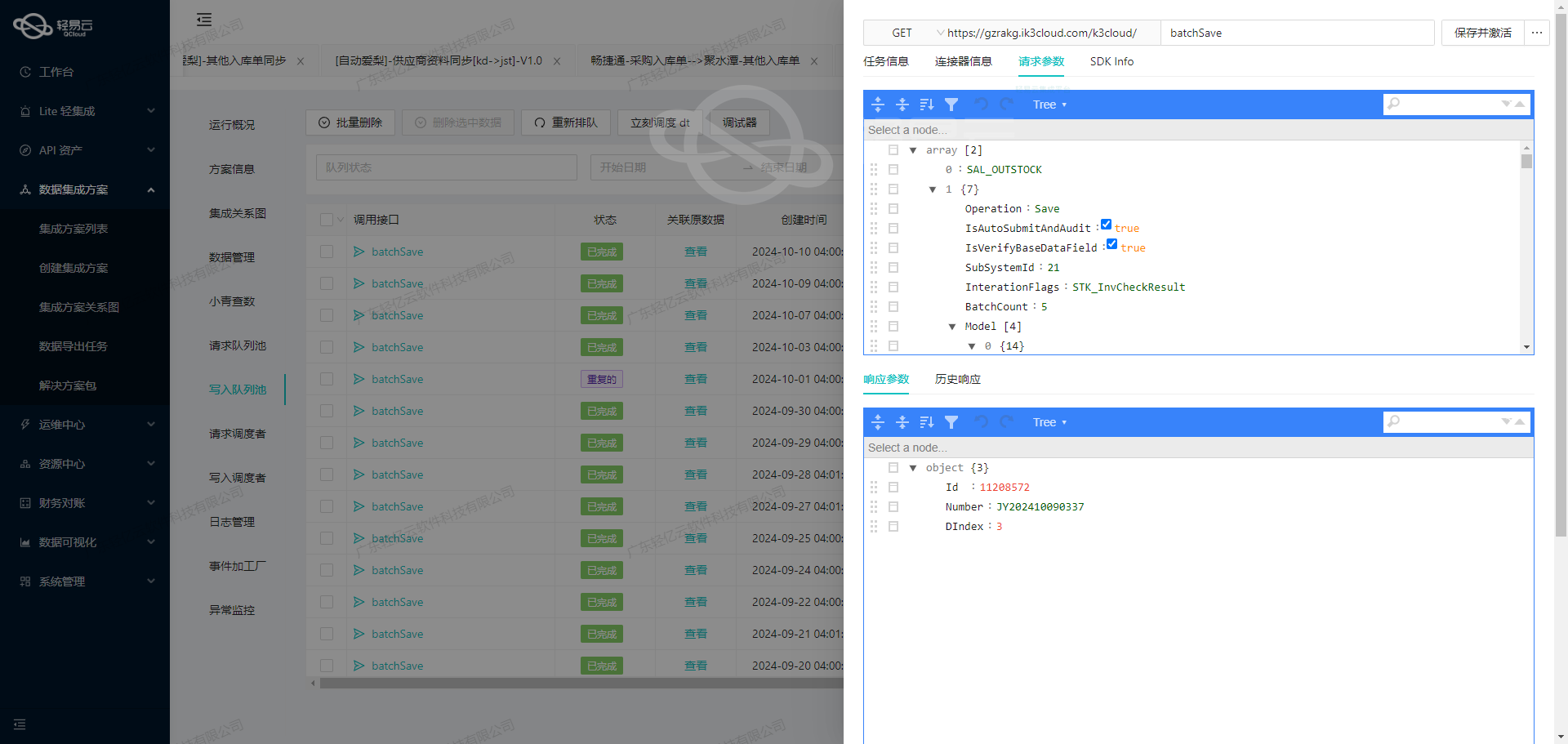
数据集成生命周期中的ETL转换:对接金蝶云星空API接口
在数据集成生命周期的第二步中,关键任务是将已经集成的源平台数据进行ETL转换,并转为目标平台金蝶云星空API接口所能够接收的格式,最终写入目标平台。本文将深入探讨这一过程中的技术细节和元数据配置。
元数据配置解析
在本次集成方案中,我们需要将聚水潭调拨数据对接到金蝶云星空的直接调拨模块。以下是详细的元数据配置:
{
"api": "batchSave",
"method": "POST",
"idCheck": true,
"operation": {
"rowsKey": "array",
"rows": 1,
"method": "batchArraySave"
},
"request": [
{"field":"FBillNo","label":"单据编号","type":"string","describe":"单据编号","value":"{io_id}"},
{"field":"FBillTypeID","label":"单据类型","type":"string","describe":"单据类型","parser":{"name":"ConvertObjectParser","params":"FNumber"},"value":"ZJDB01_SYS"},
{"field":"FBizType","label":"业务类型","type":"string","describe":"下拉列表","value":"NORMAL"},
{"field":"FTransferDirect","label":"调拨方向","type":"string","describe":"下拉列表","value":"GENERAL"},
{"field":"FTransferBizType","label":"调拨类型","type":"string","describe":"下拉列表","value":"InnerOrgTransfer"},
{"field":"FStockOutOrgId","label":"调出库存组织","type":"string","describe":"组织","parser":{"name":"ConvertObjectParser","params":"FNumber"},"value":"100"},
{"field":"FOwnerTypeOutIdHead","label":"调出货主类型","type":"string","describe":"多类别基础资料列表","value":"BD_OwnerOrg"},
{"field":"FOwnerOutIdHead","label":"调出货主","type":"","describe":"","parser":{"name":"","params":""},"value":""},
{"field":"","label":"","type":"","describe":"","parser":{"name":"","params":""},"value":""},
{"field":"","label":"","type":"","describe":"","parser":{"name":"","params":""},"value":""},
{"field":"","label":"","type":"","describe":"","parser":{"name":"","params":""},"value":""},
{"field":"","label":"","type":"","describe":"","parser":{"name":"","params":""},"value":""},
{"field":"",
"label":"",
"type":"",
"describe":"",
"parser":{
"name":"",
"params":[]
},
"value":[]
}
],
...
}API接口调用与参数配置
-
API路径与请求方式:
api:"batchSave"method:"POST"
-
操作定义:
operation: 定义了批量保存操作,其中rowsKey为"array",表示多个记录以数组形式提交;rows为1,表示每次处理一条记录;method为"batchArraySave",表示批量保存。
-
请求参数:
FBillNo: 单据编号,对应源数据中的{io_id}。FBillTypeID: 单据类型,通过ConvertObjectParser转换为目标系统识别的编码,如"ZJDB01_SYS"。FBizType: 业务类型,固定值为"NORMAL"。FTransferDirect: 调拨方向,固定值为"GENERAL"。FTransferBizType: 调拨类型,固定值为"InnerOrgTransfer"。FStockOutOrgId: 调出库存组织,通过ConvertObjectParser转换为目标系统识别的编码,如"100"。FOwnerTypeOutIdHead: 调出货主类型,固定值为"BD_OwnerOrg"。
明细信息处理
对于明细信息(如物料编码、调拨数量等),我们使用嵌套数组结构来处理:
{
...
"children":[
{
"field": "FMaterialId",
...
"parent": "FBillEntry"
},
{
...
}
],
...
}- 物料编码:通过解析器将源系统物料编码转换为目标系统识别的编码。
- 调拨数量:直接从源数据中提取,如
${batchs.qty}。 - 批号、生产日期、有效期至:根据条件进行动态赋值。
特殊字段处理
某些字段需要根据特定条件进行动态赋值,例如:
{
...
{
"field": "FLot",
...
"value": "_function case when '{link_wms_co_id}'='12926523' then '230605' when '{wms_co_id}'='12926523' then '230605' else '{{batchs.batch_no}}' end"
},
...
}这里使用了条件表达式,根据不同条件设置不同的批号。
提交与审核
最后,通过以下字段实现自动提交和审核:
{
...
{
"IsAutoSubmitAndAudit",
...
value: true
},
}以上内容展示了如何通过轻易云数据集成平台,将源平台的数据进行ETL转换,并通过金蝶云星空API接口写入目标平台。通过详细解析元数据配置和API调用参数,可以确保数据在不同系统间无缝对接,实现高效的数据集成。