钉钉数据集成到MySQL的技术实践案例
在数据信息化管理中,企业通常需要从多个系统获取数据,并进行统一存储和分析。本次案例将重点介绍如何通过轻易云数据集成平台,将钉钉的数据可靠地写入到MySQL数据库中。该方案被命名为“对账系统--供应商账号(创建供应商)”,旨在实现对钉钉中的供应商账号进行实时同步,并保证其数据的一致性和完整性。
数据源与目标:API接口概述
- 获取钉钉数据的API:
/v1.0/yida/processes/instances - 写入MySQL数据的API:
execute
主要技术难点与解决方案
-
高吞吐量的数据写入能力
- 在大规模业务场景下,需要确保从钉钉抓取的大量供应商信息可以快速、高效地写入至MySQL数据库。这要求我们必须优化读写性能,以应对此类高并发需求。
-
分页处理与限流控制
- 针对钉钉API返回结果较多时的分页问题,以及每个请求所能处理的数据量限制,我们设计了灵活的分页抓取策略。此外,通过限流控制机制避免因为频繁调用导致触发防火墙规则或服务不可用情况发生。
-
自定义数据转换逻辑
- 不同系统之间的数据格式差异,常常是集成过程中一个主要挑战。通过定制化的数据转换逻辑,每个字段、每种类型都能精确映射,使得来自不同来源的数据能够无缝融合。
-
监控与告警系统
- 实时监控整个集成过程,提供异常报警和自动重试机制,从而保障任务运行稳定。一旦出现错误,即刻定位问题源头并予以修复,大大提升了异常响应速度。
-
批量操作与定时采集
- 定期批量采集减小网络压力,同时减少对目标数据库操作频率,提高整体效率。在实际应用中,通过周期性的调度任务,实现准实时同步更新,不遗漏任何一条新增或变更的信息记录。
本着稳健、准确、快速这三大原则,该方案成功完成了复杂环境下高效、安全、灵活的数据传输工作,为后续更多业务环节提供有力支撑。接下来我们具体深入探讨实施步骤及关键技术细节——包括但不限于如何调用相关接口以及应注意的问题点。
调用钉钉接口v1.0/yida/processes/instances获取并加工数据
在数据集成生命周期的第一步中,调用源系统接口是至关重要的一环。本文将详细探讨如何通过轻易云数据集成平台调用钉钉接口v1.0/yida/processes/instances,获取并加工数据,以实现对账系统中供应商账号的创建。
API接口配置与请求参数
根据提供的元数据配置,我们需要向钉钉接口发送一个POST请求。以下是请求参数的详细配置:
- api:
v1.0/yida/processes/instances - method:
POST - number:
title - id:
processInstanceId - beatFlat:
["tableField_l61i229j"] - pagination:
{"pageSize":50} - idCheck:
true
请求体中的字段包括:
- pageSize: 分页大小,值为
50。 - pageNumber: 分页页码,值为
1。 - appType: 应用ID,值为
APP_JL611JQ2HXF8T62QJWV5。 - systemToken: 应用秘钥,值为
9I866N7106AT2IRP2KD7JBBECGH436XDNR3TK33。 - userId: 用户的userid,值为
16000443318138909。 - language: 语言,默认值为中文(zh_CN)。
- formUuid: 表单ID,值为
FORM-YZ9664D1RC62CIK3C2JDL6BZC3C0345CVV26L61。 - searchFieldJson:
- 申请类型:创建供应商
- 流水号
- 申请人
- createFromTimeGMT: 创建时间起始值,值为
2024-03-20 00:00:00。 - createToTimeGMT: 创建时间终止值,动态取当前时间。
- modifiedFromTimeGMT: 修改时间起始值。
- modifiedToTimeGMT: 修改时间终止值。
- taskId: 任务ID。
- instanceStatus: 实例状态,值为
COMPLETED。 - approvedResult: 流程审批结果,值为
agree。
数据请求与清洗
在发送请求后,我们将从钉钉接口获取到一系列流程实例的数据。这些数据需要经过清洗和转换,以确保其符合对账系统的需求。以下是清洗和转换步骤:
-
数据过滤与校验
- 根据实例状态(instanceStatus)和流程审批结果(approvedResult)进行过滤,仅保留状态为“COMPLETED”且审批结果为“agree”的记录。
- 校验每条记录的必要字段,如processInstanceId和title是否存在。
-
字段映射与转换
- 将钉钉返回的数据字段映射到对账系统所需的字段。例如,将processInstanceId映射到供应商账号ID,将title映射到供应商名称等。
-
数据格式化
- 对日期、时间等字段进行格式化处理,使其符合目标系统的格式要求。
数据写入与存储
经过清洗和转换后的数据,需要写入到对账系统中。此过程通常包括以下步骤:
-
批量写入
- 使用批量写入操作,提高数据写入效率,并减少网络传输次数。
-
错误处理与重试机制
- 在写入过程中,如果发生错误,需要记录错误日志,并根据错误类型进行相应处理,例如重试或人工干预。
-
事务管理
- 确保数据写入过程中的事务一致性,如果某一批次的数据写入失败,需要回滚已写入的数据,以保证数据的一致性和完整性。
通过上述步骤,我们可以高效地从钉钉接口获取并加工数据,实现对账系统中供应商账号的创建。这不仅提升了业务流程的自动化程度,还确保了数据的一致性和准确性。
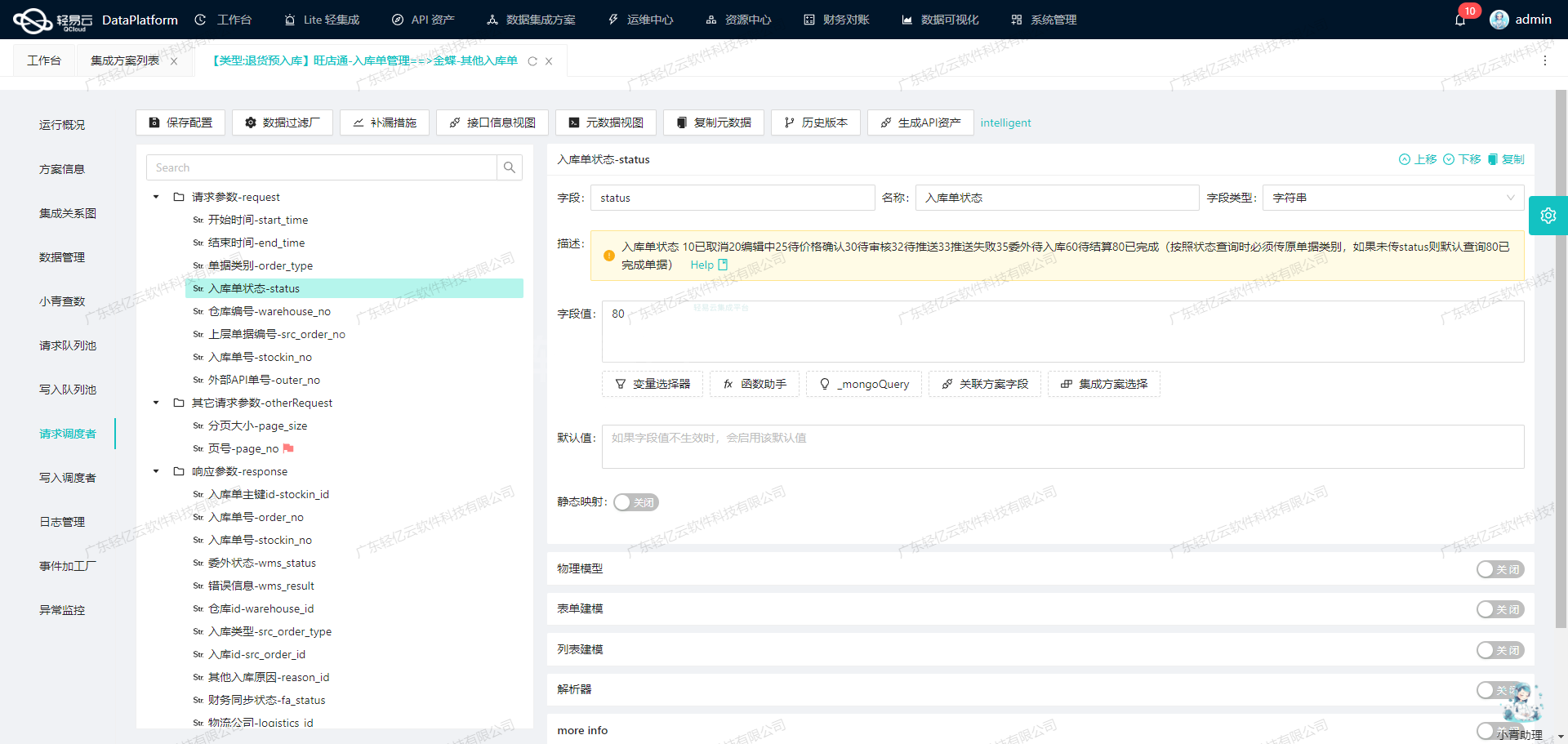
数据请求与清洗:ETL转换和写入MySQLAPI接口
在数据集成生命周期的第二步中,我们需要将已经集成的源平台数据进行ETL转换,转为目标平台 MySQLAPI 接口所能够接收的格式,并最终写入目标平台。以下是具体的技术实现细节。
元数据配置解析
元数据配置提供了详细的字段映射和转换规则。我们将通过解析这些配置,将源数据转换为目标格式。
{
"api": "execute",
"method": "POST",
"idCheck": true,
"request": [
{
"field": "main_params",
"label": "主参数",
"type": "object",
"children": [
{"field": "supplier_code", "label": "供应商编码", "type": "string", "value": "{{tableField_ktaw93bq.textField_kt4dsje0}}"},
{"field": "account_type", "label": "账户类型", "type": "int",
"value": "_function case '{{tableField_l61i229j_selectField_l61i229o}}' when '公户' then '0' when '现金账户(私户)' then '1' end"},
{"field": "account_name", "label": "账户名称", "type": "string",
"value": "{{tableField_l61i229j_textField_kxikhkxb}}"},
{"field": "bank_branch", "label": "开户行信息",
"type": "string",
"value": "{{tableField_l61i229j_textField_kxikhkxc}}"},
{"field": "account",
"label":
...数据转换逻辑
- 供应商编码:直接从源字段
{{tableField_ktaw93bq.textField_kt4dsje0}}提取。 - 账户类型:根据源字段
{{tableField_l61i229j_selectField_l61i229o}}的值进行条件判断,"公户" 转换为0,"现金账户(私户)" 转换为1。 - 账户名称:直接从源字段
{{tableField_l61i229j_textField_kxikhkxb}}提取。 - 开户行信息:直接从源字段
{{tableField_l61i229j_textField_kxikhkxc}}提取。 - 银行账号:直接从源字段
{{tableField_l61i229j_textField_kxikhkxa}}提取。 - 系统来源:固定值
4。 - 使用状态:固定值
1。 - 创建日期:使用
_function FROM_UNIXTIME(({dateField_kt82b0g7} / 1000), '%Y-%m-%d %H:%i:%s')将时间戳转换为标准日期格式。 - 创建人:固定值
1。
SQL语句构建
根据元数据配置中的 main_sql 字段,我们需要构建一个插入语句:
INSERT INTO `lhhy_srm`.`supplier_account`
(`supplier_code`, `account_type`, `account_name`, `bank_branch`, `account`, `source_Id`, `status`, `create_time`, `create_by`)
VALUES
(<{supplier_code: }>, <{account_type: }>, <{account_name: }>, <{bank_branch: }>, <{account: }>, <{source_Id: }>, <{status: }>, <{create_time: }>, <{create_by: }>);通过上述步骤,我们可以将源数据成功转换并写入到 MySQL 数据库中。此过程不仅确保了数据的一致性和完整性,还提升了数据处理的效率。
API接口调用
最后一步是通过 API 接口将转换后的数据发送到目标平台。根据元数据配置中的 API 信息,我们使用 POST 方法调用 /execute 接口:
POST /execute HTTP/1.1
Host: target-platform.com
Content-Type: application/json
{
...
}以上内容涵盖了从数据请求、清洗、转换到最终写入 MySQLAPI 接口的全过程。通过对元数据配置的深入理解和应用,我们能够高效地完成复杂的数据集成任务。