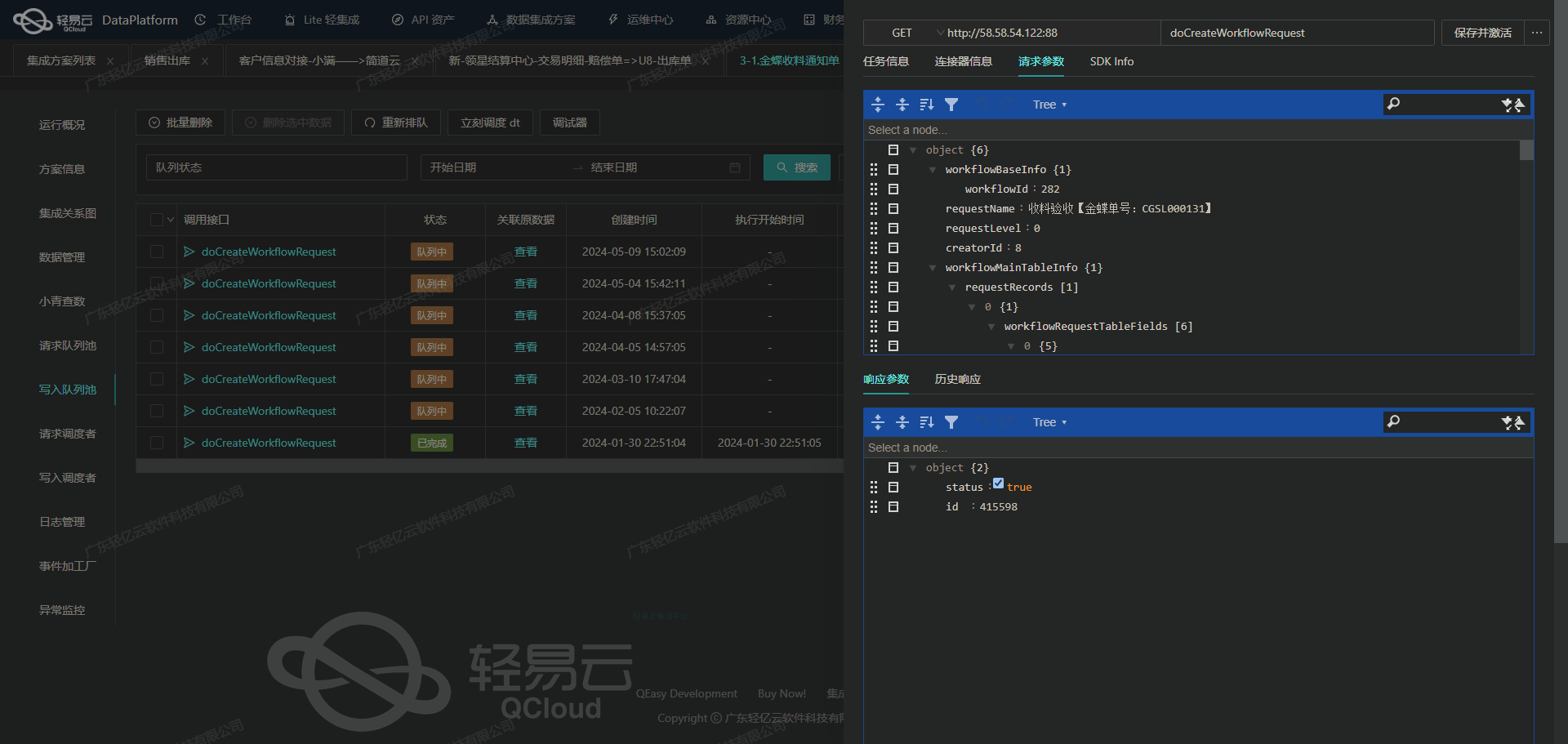
案例分享:班牛数据集成到班牛 - 查询班牛退换原因-责任方细分
在此次系统对接集成案例中,我们将重点探讨如何通过API接口,对接并实现"查询班牛退换原因-责任方细分"的数据集成。在这个过程中,利用了高吞吐量的数据写入能力以及实时监控等功能,使得大量数据能够快速而精确地被集成到班牛系统中,大大提升了数据处理的时效性和可靠性。
首先,任务集中在调用column.list API以获取所需的字段信息。对于这个步骤,使用轻易云平台提供的可视化数据流设计工具,可以直观地配置从呼叫API到解析返回结果的一系列操作,有效减少了人为配置错误。此外,通过定制化的数据转换逻辑,将字段信息映射到我们的业务需求结构中。这不仅简化了后续处理,还确保了数据的一致性和准确度。
其次,在批量写入数据至班牛前,需要考虑其分页与限流问题。依赖于平台自带的监控和告警系统,我们可以实时跟踪每个请求的状态,并迅速采取措施应对异常情况。例如,当检测到请求超时或频率受限时,可自动触发重试机制,以保证每条记录均能成功写入。这一机制极大程度上提高了流程的稳定性,同时避免遗漏或重复提交的问题,为业务连续性提供了坚实保障。
最后,把整理后的数据信息通过调用workflow.task.create API进行批量写入。此阶段尤为关键,因为它决定着最终目标系统的数据完整度与可靠度。在这里,高吞吐量的数据处理特性能显著缩短整个过程时间,从而更快地产生有效产出。同时,通过集中调配API资产管理功能,可以全面掌握每个接口调用的资源使用情况,实现优化配置及合理控制。
该技术方案不仅满足当前业务需求,更具备良好的扩展潜力,为未来更多复杂场景下的数据集成打下坚实基础。在随后的内容中,将详细阐述每一个具体步骤及其实现方式。
调用班牛接口column.list获取并加工数据
在数据集成生命周期的第一步中,调用源系统接口是至关重要的一环。本文将详细探讨如何通过轻易云数据集成平台调用班牛的column.list接口,并对返回的数据进行加工处理。
接口调用配置
首先,我们需要配置元数据以调用班牛的column.list接口。以下是元数据配置的关键部分:
{
"api": "column.list",
"effect": "QUERY",
"method": "GET",
"number": "column_id",
"id": "column_id",
"request": [
{
"field": "project_id",
"label": "project_id",
"type": "string",
"value": "25821"
}
],
"buildModel": true,
"autoFillResponse": true,
"condition": [
[
{
"field": "column_id",
"logic": "eqv2",
"value": "37581"
}
]
],
"beatFlat": ["relation_options"]
}请求参数详解
- api: 指定要调用的API接口,这里为
column.list。 - effect: 定义操作类型,这里为查询(QUERY)。
- method: HTTP请求方法,这里使用GET。
- number 和 id: 用于标识数据记录的字段,这里均为
column_id。 - request: 请求参数列表,包含一个字段
project_id,其值为25821。 - buildModel: 是否构建模型,这里设置为true。
- autoFillResponse: 是否自动填充响应数据,这里设置为true。
- condition: 查询条件,这里指定了一个条件,即
column_id等于37581。 - beatFlat: 指定需要平展处理的字段,这里为
relation_options。
数据请求与清洗
在配置好元数据后,我们通过轻易云平台发起HTTP GET请求,向班牛系统获取指定项目(project_id为25821)下特定列(column_id为37581)的信息。
GET /api/column.list?project_id=25821&column_id=37581响应示例:
{
"status": 200,
"data": {
"columns": [
{
"column_id": 37581,
"name": "退换原因",
...
"relation_options": [
{"id":1, "name":"质量问题"},
{"id":2, "name":"尺寸不合适"},
...
]
}
]
}
}在获取到响应数据后,需要对其进行清洗和转换,以便后续处理。这里我们重点关注的是对 relation_options 字段的平展处理。
数据转换与写入
为了便于分析和使用,我们将 relation_options 字段中的每个选项单独提取出来,并生成新的记录。通过轻易云平台的自动填充功能,可以简化这一过程。
转换后的数据结构示例:
[
{
"column_id": 37581,
"option_id": 1,
"option_name": "质量问题"
},
{
"column_id": 37581,
"option_id": 2,
"option_name": "尺寸不合适"
},
...
]这些转换后的数据可以直接写入目标系统或数据库中,以供进一步分析和使用。
总结
通过上述步骤,我们成功地调用了班牛的 column.list 接口,获取并加工了所需的数据。这一过程展示了轻易云数据集成平台在处理异构系统间数据集成时的强大能力和灵活性。

使用轻易云数据集成平台进行ETL转换并写入班牛API接口
在数据集成过程中,ETL(Extract, Transform, Load)是一个关键步骤,特别是在将源平台的数据转换为目标平台可接收的格式时。本文将详细探讨如何使用轻易云数据集成平台,将已经集成的源平台数据进行ETL转换,转为班牛API接口所能够接收的格式,并最终写入目标平台。
数据请求与清洗
在数据请求阶段,我们从源系统中获取原始数据。此过程通常涉及到对多个异构系统的数据进行抽取和初步清洗,以确保数据的完整性和一致性。在轻易云数据集成平台上,这一步骤通过配置相应的数据源和任务来实现。
数据转换与写入
一旦数据被成功抽取并清洗,我们需要将其转换为班牛API接口所能接受的格式。根据提供的元数据配置,我们需要调用班牛的workflow.task.create API,该API通过HTTP POST方法执行,并且需要进行ID检查。
元数据配置如下:
{
"api": "workflow.task.create",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}配置ETL流程
- 提取(Extract):从源系统中提取所需的数据。例如,从ERP系统中提取退换货原因及责任方细分信息。
- 转换(Transform):将提取到的数据转换为班牛API所需的格式。这一步骤包括字段映射、数据类型转换、以及必要的数据校验。
- 加载(Load):通过调用班牛API,将转换后的数据写入目标系统。
以下是一个具体的技术案例:
步骤一:提取数据
假设我们从ERP系统中提取到如下JSON格式的数据:
{
"returnReason": "产品质量问题",
"responsibleParty": "供应商"
}步骤二:转换数据
根据班牛API的要求,我们需要将上述JSON数据转换为符合其接口规范的格式。假设班牛API要求的数据格式如下:
{
"taskName": "退换货处理",
"taskDetails": {
"reason": "产品质量问题",
"partyResponsible": "供应商"
}
}在轻易云平台上,我们可以通过编写自定义脚本或使用内置的转换工具来实现这一点。以下是一个简单的JavaScript示例,用于完成这一转换:
function transformData(sourceData) {
return {
taskName: "退换货处理",
taskDetails: {
reason: sourceData.returnReason,
partyResponsible: sourceData.responsibleParty
}
};
}
let sourceData = {
returnReason: "产品质量问题",
responsibleParty: "供应商"
};
let transformedData = transformData(sourceData);
console.log(JSON.stringify(transformedData));步骤三:加载数据
最后,通过HTTP POST方法调用班牛API,将转换后的数据写入目标系统。以下是一个使用Node.js发起HTTP请求的示例:
const https = require('https');
const postData = JSON.stringify({
taskName: '退换货处理',
taskDetails: {
reason: '产品质量问题',
partyResponsible: '供应商'
}
});
const options = {
hostname: 'api.banniu.com',
port: 443,
path: '/workflow/task/create',
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Content-Length': postData.length
}
};
const req = https.request(options, (res) => {
let data = '';
res.on('data', (chunk) => {
data += chunk;
});
res.on('end', () => {
console.log(`Response from API: ${data}`);
});
});
req.on('error', (e) => {
console.error(`Problem with request: ${e.message}`);
});
req.write(postData);
req.end();总结
通过以上步骤,我们成功地完成了从源系统到目标系统的数据ETL过程,并通过调用班牛API接口,实现了最终的数据写入。这一过程充分利用了轻易云数据集成平台提供的全生命周期管理功能,使得整个操作透明、高效且可监控。