钉钉数据集成到SQL Server的技术案例分享
在企业信息化管理中,数据的高效流动和准确处理至关重要。本文将聚焦于一个具体的系统对接集成案例:如何将钉钉的数据集成到SQL Server,以实现查询供应商和往来款付款申请的功能。
为了确保数据集成过程的顺利进行,我们利用了轻易云数据集成平台的一系列特性,包括高吞吐量的数据写入能力、实时监控与告警系统、自定义数据转换逻辑以及可视化的数据流设计工具。这些特性不仅提升了数据处理的时效性,还保证了每个环节的透明度和可控性。
在本次案例中,我们主要使用了钉钉提供的API接口topapi/processinstance/get来获取所需的数据,并通过SQL Server API exec将这些数据写入目标数据库。整个过程中,我们特别关注以下几个技术要点:
- 定时可靠地抓取钉钉接口数据:通过设置定时任务,确保从钉钉接口获取的数据不漏单。
- 批量集成数据到SQL Server:支持大规模数据快速写入,提高整体处理效率。
- 处理分页和限流问题:针对钉钉API返回的大量分页结果,设计合理的分页策略,并应对API调用频率限制。
- 自定义数据转换逻辑:根据业务需求,对从钉钉获取的数据进行格式转换,以适应SQL Server的数据结构。
- 异常处理与错误重试机制:在对接过程中,建立健全的异常捕获和重试机制,确保系统稳定运行。
通过以上技术手段,我们成功实现了从钉钉到SQL Server的数据无缝对接,为企业提供了一套高效、可靠的数据管理解决方案。在后续章节中,将详细介绍具体实施步骤及技术细节。
调用钉钉接口topapi/processinstance/get获取并加工数据
在轻易云数据集成平台的生命周期中,调用源系统接口是至关重要的一步。本文将深入探讨如何通过调用钉钉接口topapi/processinstance/get来查询供应商和往来款付款申请,并对获取的数据进行加工处理。
钉钉接口调用配置
首先,我们需要了解元数据配置中的关键参数:
api: "topapi/processinstance/get"effect: "QUERY"method: "POST"number: "number"id: "id"idCheck: trueautoFillResponse: true
这些参数定义了我们如何与钉钉API进行交互。具体来说,api指定了要调用的API路径,method定义了HTTP请求方法为POST,其他参数则用于确保请求和响应的正确性。
数据请求与清洗
在实际操作中,我们首先需要构建一个有效的HTTP POST请求,以便从钉钉系统中获取所需的数据。以下是关键步骤:
- 构建请求体:根据业务需求,将必要的查询条件(如流程实例ID)填入请求体。
- 发送请求:使用轻易云平台提供的HTTP客户端功能发送POST请求。
- 接收响应:解析返回的数据,并检查是否包含预期的信息。
例如,请求体可能包含如下内容:
{
"process_instance_id": "example_id_12345"
}在接收到响应后,需要对数据进行初步清洗。这包括但不限于:
- 检查返回状态码是否为200,以确认请求成功。
- 验证返回的数据结构是否符合预期。
- 提取出有用的信息,如供应商名称、付款金额等。
数据转换与写入
一旦完成数据清洗,就可以进入数据转换阶段。在这个阶段,我们需要将原始数据转换为目标系统(如SQL Server)所能接受的格式。这通常涉及以下几项工作:
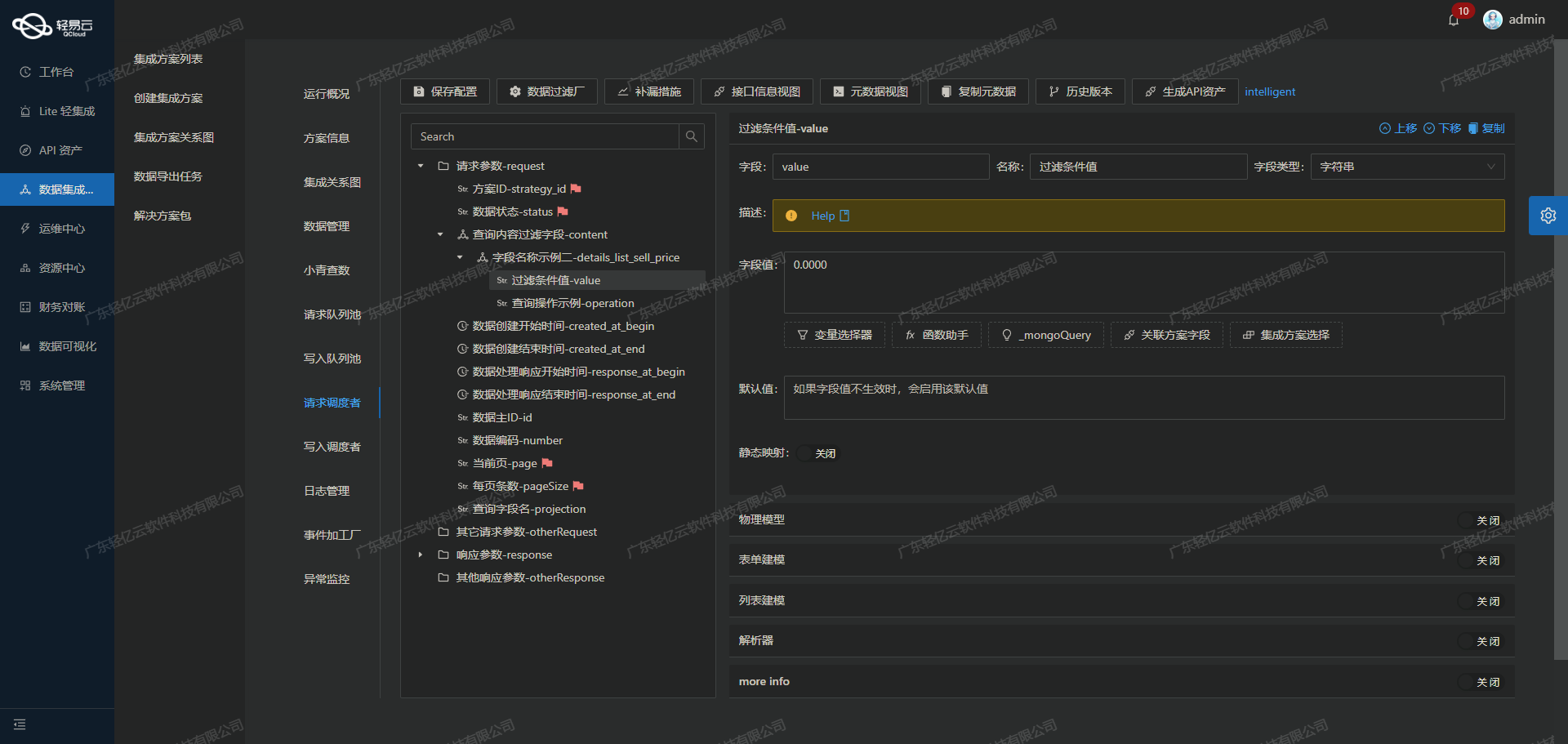
- 字段映射:将钉钉返回的数据字段映射到SQL Server表中的相应字段。例如,将"vendor_name"映射到数据库中的"SupplierName"列。
- 数据类型转换:确保所有字段的数据类型匹配。例如,将字符串类型的日期转换为SQL Server中的DATETIME类型。
- 批量处理:为了提高效率,可以将多条记录打包成一个批次进行处理。
举例来说,如果从钉钉获取到如下JSON数据:
{
"vendor_name": "ABC Corp",
"payment_amount": 1000,
"payment_date": "2023-10-01T12:00:00Z"
}我们需要将其转换为适合SQL Server插入的格式:
INSERT INTO Payments (SupplierName, Amount, PaymentDate) VALUES ('ABC Corp', 1000, '2023-10-01 12:00:00')异常处理与重试机制
在整个过程中,异常处理和重试机制也是不可忽视的重要环节。常见的问题包括网络超时、API限流以及数据格式不匹配等。针对这些问题,可以采取以下措施:
- 网络超时:设置合理的超时时间,并在超时后自动重试一定次数。
- API限流:根据钉钉API文档,合理设置每秒钟最大请求数,并实现限流控制逻辑。
- 数据格式不匹配:在解析和转换过程中加入严格的数据验证逻辑,一旦发现异常立即记录日志并触发告警。
例如,对于网络超时,可以采用如下伪代码实现重试机制:
for attempt in range(max_retries):
try:
response = send_request()
if response.status_code == 200:
process_response(response)
break
except TimeoutError:
log_warning("Request timed out, retrying...")实时监控与日志记录
为了确保整个过程透明可控,实时监控和日志记录是必不可少的。通过轻易云平台提供的集中监控和告警系统,可以实时跟踪每个集成任务的状态和性能。一旦出现异常情况,例如某个任务执行时间过长或失败次数过多,系统会立即发出告警通知相关人员及时处理。
此外,通过详细的日志记录,可以追溯每一次API调用及其结果,为后续问题排查提供依据。例如,每次成功或失败的API调用都应记录下相关信息,包括时间戳、请求参数、响应结果等。
综上所述,通过合理配置元数据、精细化管理数据请求与清洗、灵活应用异常处理机制以及实时监控与日志记录,我们可以高效地完成从钉钉接口获取并加工处理供应商和往来款付款申请的数据集成任务。这不仅提升了业务透明度,也极大提高了整体效率。
数据ETL转换与写入SQL Server API接口的技术实现
在数据集成平台的生命周期中,数据的ETL(提取、转换、加载)过程至关重要。通过轻易云数据集成平台,我们可以高效地将钉钉系统中的数据转换并写入到目标平台——SQL Server。本案例将详细探讨如何利用API接口实现这一过程。
1. 数据提取与清洗
首先,从钉钉系统中提取供应商和往来款付款申请的数据。通过调用钉钉接口 topapi/processinstance/get,我们可以获取所需的原始数据。这一步需要特别注意处理接口的分页和限流问题,以确保数据完整性和稳定性。
2. 数据转换
在数据转换阶段,我们需要将提取的数据格式化为SQL Server API能够接受的格式。这包括日期格式转换、金额单位换算以及字段映射等。以下是关键元数据配置:
{
"field": "Date",
"label": "日期",
"type": "string",
"value": "_function DATE_FORMAT('{{extend.finish_time}}', '%Y-%m-%d')"
}上述配置示例展示了如何将日期字段从钉钉的时间戳格式转换为SQL Server所需的YYYY-MM-DD格式。此外,还需要将其他字段如年度、期间、凭证总金额等进行类似的处理。
3. 构建主参数与扩展参数
为了确保数据能够正确写入SQL Server,我们需要构建主参数和扩展参数。主参数包含了凭证信息,而扩展参数则包括了借方和贷方明细。以下是部分配置示例:
{
"field": "main_params",
"label": "主参数",
"type": "object",
"children": [
{
"field": "Amount",
"label": "凭证总金额",
"type": "string",
"value": "{{金额(元)}}"
},
{
"field": "Note",
"label": "摘要",
"type": "string",
"value": "{{extend.finish_time}}付{{收款人全称}}{{付款事由}}"
}
]
}在扩展参数中,特别要注意核算项目ID(FDetailID)的获取,这通常需要通过查询MongoDB或其他数据库来实现,以确保数据的一致性和准确性。
{
"field": "FDetailID",
"label": "核算项目ID",
"type": "int",
"value": "_mongoQuery findField=content.FDetailID where={\"content.SupFName\":{\"$eq\":\"{{收款人全称}}\"}}"
}4. 数据写入
完成数据转换后,通过API接口将数据写入SQL Server。我们使用存储过程(Stored Procedure)来执行插入操作。以下是主语句和扩展语句配置示例:
{
"field": "main_sql",
"label": "主语句",
"type": "string",
"value":"exec sp_AddVoucher :Date,:Year,:period,:Group,:entryCount,:Amount,:Note,:BillUser,:detailNumbers"
}{
"field":"extend_sql_1",
"label":"1:1扩展语句",
"type":"string",
"value":"exec sp_AddVoucherEntry :lastInsertId,:FEntryID,:FNote,:AccountNumber,:AccountNumber1,:FCurrencyNumber,:FExchangeRate,:FDC,:FAmountFor,:Famount,:Fquantity,:FUnitPrice,:FMeasureUnitNumber,:FDetailID"
}技术要点与优化策略
- 高吞吐量支持:轻易云平台支持高吞吐量的数据写入能力,确保大量数据能够快速集成到SQL Server。
- 实时监控与告警:通过集中监控和告警系统,实时跟踪数据集成任务的状态和性能,及时发现并处理异常。
- 自定义转换逻辑:支持自定义数据转换逻辑,以适应特定业务需求和复杂的数据结构。
- 错误重试机制:在对接过程中,如遇到异常情况,可实现错误重试机制,确保数据可靠传输。
通过以上步骤,我们可以高效地完成从钉钉系统到SQL Server的数据ETL转换及写入过程,实现不同系统间的数据无缝对接。这不仅提升了业务透明度,还极大提高了工作效率。