聚水潭订单数据集成到轻易云平台的实践分享
在本案例中,我们将详细剖析如何通过轻易云数据集成平台,实现聚水潭(Jushuitan)订单数据的高效对接。具体接口为orders.out.simple.query,它负责从聚水潭系统中提取订单信息,并同步至我们设定好的目标环境。在此过程中,需要有效处理分页、限流和数据格式差异等技术细节,以确保不漏单并且快速写入大量订单数据。
一、调用聚水潭API获取订单数据
为了实现准确的数据抓取,我们选择了聚水潭提供的orders.out.simple.query接口。该接口能够在指定时间段内读取所有新生成或更新的订单信息,满足批量抓取需求。同时,需要注意API的分页和限流特性,我们采用了轮询机制来确保完整的数据拉取。
def fetch_orders(api_key, start_time, end_time):
url = 'https://api.jushuitan.com/orders.out.simple.query'
params = {
'api_key': api_key,
'start_time': start_time,
'end_time': end_time,
... # 其他必要参数
}
response = requests.get(url, params=params)
if response.status_code == 200:
return response.json()
else:
handle_error(response)二、大规模多线程处理与错误重试机制
在面对大量订单需要集中写入至轻易云平台时,多线程批量处理是不可或缺的一部分。此外,在可能出现网络不稳定或者其他异常情况时,必须设计可靠的错误重试机制,以提高整体运行效率和成功率。
from concurrent.futures import ThreadPoolExecutor
def write_to_platform(order_data, platform_api_url):
try:
# 调用轻易云平台写入API逻辑,此处仅示例空操作替代.
pass
except Exception as e:
retry_write(order_data)
def batch_process(orders):
with ThreadPoolExecutor(max_workers=10) as executor:
futures = [executor.submit(write_to_platform, order) for order in orders]
for future in futures:
print(future.result())三、实时监控与日志记录
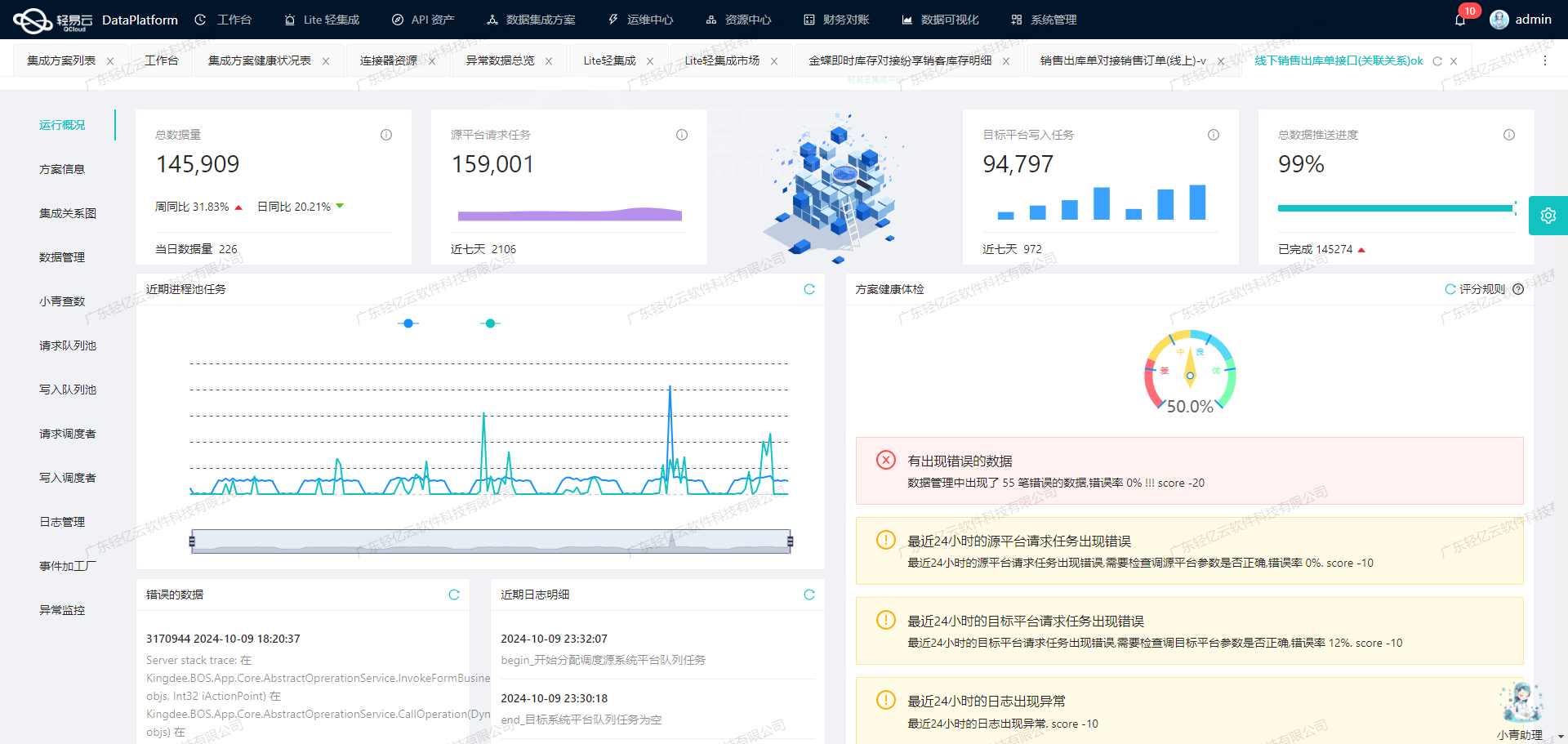
通过启用实时监控与日志记录功能,可以实时查看每一条数据流动情况以及处理状态,从而更快发现并解决潜在问题。这种透明化管理不仅提高业务透明度,还显著提升整个项目实施过程中的安全性及稳定性。
总结而言,通过精确调用聚水潭接口进行周期性的定时抓取、多线程批量处理及完善的数据同步策略,可以显著提升从源头到目标数据库间的大规模、高频次数据信
调用聚水潭接口orders.out.simple.query获取并加工数据的技术实现
在数据集成过程中,调用源系统接口是至关重要的一步。本文将详细探讨如何通过轻易云数据集成平台调用聚水潭的orders.out.simple.query接口来获取订单数据,并对其进行初步加工。
接口调用配置
首先,我们需要根据提供的元数据配置来设置API调用参数。以下是元数据配置的详细内容:
{
"api": "orders.out.simple.query",
"method": "POST",
"number": "o_id",
"id": "o_id",
"pagination": {
"pageSize": 100
},
"idCheck": true,
"request": [
{"field":"shop_id","label":"店铺编码","type":"string"},
{"field":"is_offline_shop","label":"shop_id为0且is_offline_shop为true查询线下店铺单据","type":"string"},
{"field":"status","label":"单据状态","type":"string","value":"Confirmed"},
{"field":"modified_begin","label":"修改开始时间","type":"string","value":"{{LAST_SYNC_TIME|datetime}}"},
{"field":"modified_end","label":"修改结束时间","type":"string","value":"{{CURRENT_TIME|datetime}}"},
{"field":"so_ids","label":"线上单号","type":"string","parser":{"name":"StringToArray","params":","}},
{"field":"page_index","label":"页数","type":"string","value":"{PAGINATION_START_PAGE}"},
{"field":"page_size","label":"每页行数","type":"string","value":"{PAGINATION_PAGE_SIZE}"}
]
}参数解析与设置
- API及请求方法:我们使用的是
orders.out.simple.queryAPI,采用POST方法进行请求。 - 分页处理:每次请求的数据量由
page_size字段控制,这里设置为100条记录。分页索引由page_index字段控制,从第一页开始。 - 时间范围:通过
modified_begin和modified_end字段设定查询的时间范围,分别使用上次同步时间和当前时间。 - 状态过滤:固定查询状态为“Confirmed”的订单。
- 其他参数:包括店铺编码、是否线下店铺、线上单号等。
请求示例
根据上述配置,我们可以构建一个具体的请求示例:
{
"shop_id": "12345",
"is_offline_shop": "false",
"status": "Confirmed",
"modified_begin": "2023-10-01T00:00:00Z",
"modified_end": "2023-10-02T00:00:00Z",
"so_ids": ["SO123", "SO124"],
"page_index": 1,
"page_size": 100
}数据获取与初步加工
在成功调用API并获取到订单数据后,需要对数据进行初步加工。这包括但不限于以下几个步骤:
- 数据清洗:去除无效或重复的数据,根据业务需求筛选出有效记录。
- 格式转换:将日期、金额等字段转换为标准格式,以便后续处理。
- 字段映射:根据目标系统的要求,对字段进行重命名或重新排列。
例如,对于获取到的一条订单记录,可以进行如下处理:
{
"order_id": "O1234567890",
"shop_id": "12345",
...
}经过清洗和转换后,可能变为:
{
"订单编号": "O1234567890",
"店铺编码": "12345",
...
}异常处理与日志记录
在实际操作中,可能会遇到各种异常情况,如网络故障、接口超时等。为了确保数据集成过程的稳定性,需要添加异常处理机制,并记录详细日志以便排查问题。例如:
try:
response = requests.post(api_url, json=request_payload)
response.raise_for_status()
except requests.exceptions.RequestException as e:
logging.error(f"API request failed: {e}")通过以上步骤,我们可以高效地调用聚水潭的订单查询接口,并对返回的数据进行初步加工,为后续的数据转换与写入奠定基础。
使用轻易云数据集成平台进行ETL转换并写入目标平台的技术案例
在数据集成生命周期的第二步,我们需要将已经从源平台(例如聚水潭订单查询接口)获取到的数据进行ETL(提取、转换、加载)处理,并最终写入目标平台。本文将详细介绍如何利用轻易云数据集成平台的API接口进行这一过程。
数据提取与初步清洗
首先,我们从聚水潭订单查询接口获取原始数据。假设我们已经通过API请求成功获取了订单数据,接下来需要对这些数据进行初步清洗和转换,以确保其符合目标平台所需的格式。
{
"order_id": "123456",
"customer_name": "张三",
"order_date": "2023-10-01",
"total_amount": 150.75,
"items": [
{
"item_id": "A001",
"quantity": 2,
"price": 50.25
},
{
"item_id": "B002",
"quantity": 1,
"price": 50.25
}
]
}数据转换
接下来,我们需要将上述数据转换为目标平台轻易云集成平台API接口所能接收的格式。根据元数据配置,我们需要使用POST方法,并且开启idCheck以确保数据唯一性。
转换规则示例:
- 字段重命名:将
order_id重命名为id,customer_name重命名为name。 - 日期格式转换:将
order_date字段中的日期格式从“YYYY-MM-DD”转换为“YYYYMMDD”。 - 金额计算:重新计算订单总金额,确保其精确度。
{
"id": "123456",
"name": "张三",
"date": "20231001",
"amount": 150.75,
"items_detail": [
{
"product_id": "A001",
"qty": 2,
"unit_price": 50.25
},
{
"product_id": "B002",
"qty": 1,
"unit_price": 50.25
}
]
}数据写入
完成数据转换后,我们使用轻易云集成平台提供的API接口,将这些处理后的数据写入目标平台。以下是一个具体的API调用示例:
import requests
url = 'https://api.qingyiyun.com/data/write'
headers = {'Content-Type': 'application/json'}
payload = {
'api': '空操作',
'method': 'POST',
'idCheck': True,
'data': {
'id': '123456',
'name': '张三',
'date': '20231001',
'amount': 150.75,
'items_detail': [
{
'product_id': 'A001',
'qty': 2,
'unit_price': 50.25
},
{
'product_id': 'B002',
'qty': 1,
'unit_price': 50.25
}
]
}
}
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print('Data successfully written to target platform.')
else:
print('Failed to write data:', response.text)在上述代码中,我们通过HTTP POST方法将处理后的订单数据发送到目标平台。为了确保数据唯一性,开启了idCheck选项,这样可以避免重复记录的问题。
实时监控与调试
在实际操作过程中,实时监控和调试是必不可少的环节。轻易云集成平台提供了全透明可视化的操作界面,可以实时监控每个环节的数据流动和处理状态。如果出现错误或异常情况,可以快速定位并解决问题,提高整体效率和可靠性。
通过以上步骤,我们成功地实现了从源平台到目标平台的数据ETL过程。这个过程不仅保证了数据的一致性和准确性,还极大提升了业务透明度和效率,为企业的数据管理提供了强有力的支持。