SQL Server数据集成到轻易云平台的技术案例分享
在大规模数据处理与整合任务中,SQL Server作为企业级数据库解决方案扮演了重要角色,而如何高效地将其数据集成到轻易云平台成为了众多系统对接项目中的一个关键课题。本篇文章将围绕查询AD流程中间表--测试这一具体案例,深入探讨实现该目标的技术细节。
本次集成任务主要通过调用SQL Server API接口进行数据查询(select),并借助轻易云的数据写入API完成数据迁移和存储。核心挑战包括:确保大量数据快速且无遗漏地写入、定时可靠抓取SQL Server接口数据、处理分页与限流问题以及应对两者之间的数据格式差异。以下是本次案例中的几个关键技术点:
-
高吞吐量的数据写入
- 为了保证在较短时间内能大量导出SQL Server中的业务信息,我们采用了批量读取和并行处理的方法,通过配置高吞吐量写入机制,将获取的数据迅速传输至轻易云平台,实现应用性能的最大化。
-
实时监控与日志记录
- 数据集成过程中启用了实时监控功能,这不仅涵盖每一次API调用后的状态码及响应内容,还通过集中化日志模块,对各个环节进行详细记录,以便后续问题诊断和优化调整。
-
自定义转换逻辑
- 由于源系统(SQL Server)与目标系统(轻易云平台)之间存在一定的结构差异,因而我们引入了一套灵活可调的自定义映射规则。在实际操作中,通过编排特定转换逻辑,使得不同类型字段可以准确匹配,从而确保导出的数据信息完整且符合预期格式。
-
异常检测及重试机制
- 在面对网络抖动或服务器暂时不可用等意外状况下,本次方案也设计了一套完善的异常检测与错误重试机制。当出现异常时,能够自动识别并发起重新请求,以保障整体任务执行连续性,不会因单个失败操作影响全局流程稳定性。
以上几个方面构成了此次“查询AD流程中间表--测试”方案实施的重要基础,即使面对复杂多变的数据环境,也能保障平滑连接和高效管理。在接下来的章节里,将逐步详解每一部分具体实现细节。
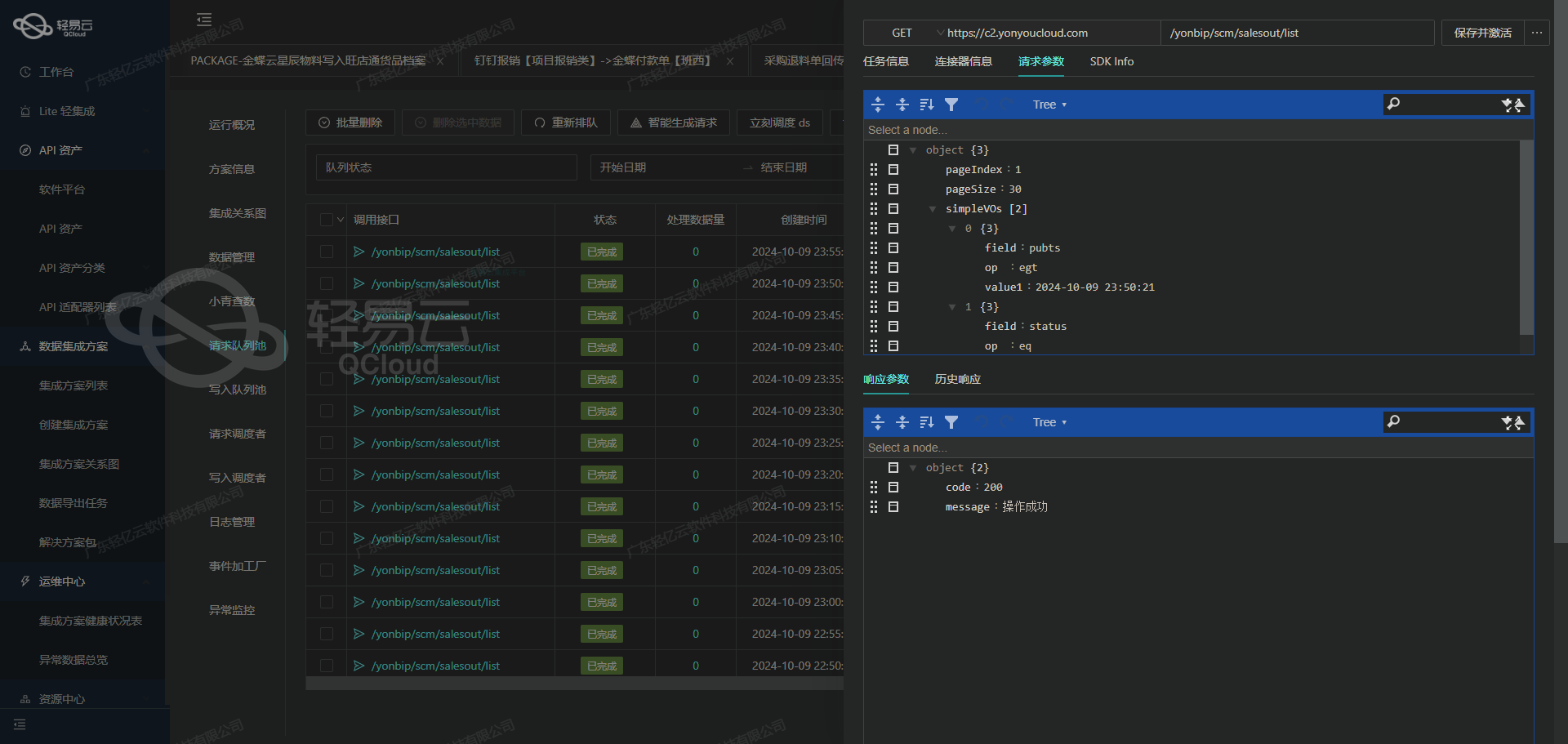
使用轻易云数据集成平台调用SQL Server接口获取并加工数据
在轻易云数据集成平台的生命周期中,第一步是从源系统获取数据。本文将详细探讨如何通过调用SQL Server接口select来获取并加工数据。
元数据配置解析
元数据配置是实现数据集成的关键,它定义了如何从源系统提取数据。以下是我们使用的元数据配置:
{
"api": "select",
"effect": "QUERY",
"method": "POST",
"number": "requestname",
"id": "requestid",
"idCheck": true,
"request": [
{
"field": "main_params",
"label": "main_params",
"type": "object",
"describe": "111"
}
],
"otherRequest": [
{
"field": "main_sql",
"label": "main_sql",
"type": "string",
"describe": "111",
"value":
"select requestid,workflowid as e9_workflowId,requestname,currentnodeid,creater as e9_user_id from workflow_requestbase where (workflowid='515' and currentnodeid in ('4200','4196'))",
"default":
"select requestid,workflowid as e9_workflowId,requestname,currentnodeid,creater as e9_user_id from workflow_requestbase where lastoperatedate>=:startupdatetime and lastoperatedate<=:endupdatetime and ((workflowid=273 and currentnodeid=1906))"
}
],
"autoFillResponse": true
}调用SQL Server接口获取数据
- API调用方式:该配置使用
POST方法调用SQL Server接口进行查询操作。 - 查询语句:
main_sql字段中定义了具体的SQL查询语句,用于从数据库中提取所需的数据。- 默认查询语句:
select requestid, workflowid as e9_workflowId, requestname, currentnodeid, creater as e9_user_id from workflow_requestbase where lastoperatedate >= :startupdatetime and lastoperatedate <= :endupdatetime and ((workflowid = 273 and currentnodeid = 1906)) - 自定义查询语句:
select requestid, workflowid as e9_workflowId, requestname, currentnodeid, creater as e9_user_id from workflow_requestbase where (workflowid = '515' and currentnodeid in ('4200', '4196'))
- 默认查询语句:
数据请求与清洗
在实际操作中,我们需要确保请求参数和SQL语句中的占位符(如:startupdatetime和:endupdatetime)正确替换为实际值。以下是一个示例请求:
{
"main_params": {
// 参数对象,可以包含其他自定义参数
},
// SQL 查询语句可以动态传入,也可以使用默认值
// 如果不传入 main_sql,则使用默认 SQL 查询语句
}数据转换与写入
在获取到原始数据后,轻易云平台会根据配置自动进行数据转换。例如,将字段workflowid重命名为e9_workflowId,将字段creater重命名为e9_user_id。这些转换规则在SQL查询语句中已经定义好,无需额外处理。
自动填充响应
配置中的autoFillResponse: true表示平台会自动将查询结果填充到响应中,简化了开发工作量。
实际应用案例
假设我们需要从一个工作流系统中提取特定流程的数据,并将其整合到另一个系统中。通过上述配置,我们可以轻松实现这一目标:
- 配置元数据:按照上述元数据格式进行配置。
- 发送请求:通过轻易云平台发送POST请求,执行SQL查询。
- 接收并处理响应:平台自动处理响应,将结果转换为目标格式。
这种方式不仅提高了开发效率,还确保了数据的一致性和准确性。在实际项目中,这种方法广泛应用于跨系统的数据整合和业务流程优化。
通过以上步骤,我们成功实现了从SQL Server接口获取并加工数据的过程。这一过程充分利用了轻易云平台的优势,使得复杂的数据集成任务变得简单高效。
数据转换与写入:使用轻易云数据集成平台API接口
在数据集成生命周期的第二步中,我们需要将已经从源平台获取并清洗的数据进行ETL转换,最终写入目标平台。本文将重点探讨如何利用轻易云数据集成平台的API接口实现这一过程。
API接口元数据配置解析
我们首先来看一下提供的元数据配置:
{
"api": "写入空操作",
"effect": "EXECUTE",
"method": "POST",
"idCheck": true
}api: 指定了目标API接口名称,这里是“写入空操作”。effect: 定义了操作的效果类型,这里是执行(EXECUTE)。method: HTTP请求方法,这里是POST。idCheck: 表示是否需要进行ID校验,这里为true。
数据转换过程
在ETL(Extract, Transform, Load)过程中,转换(Transform)是关键步骤之一。我们需要确保源平台的数据格式能够符合目标API接口所需的格式。
-
数据提取与清洗:
- 从AD流程中间表中提取原始数据。
- 清洗数据,去除无效或冗余信息。
-
数据转换:
- 根据目标API接口要求,对数据进行结构化处理。例如,如果目标API需要JSON格式的数据,我们需要将原始数据转为JSON对象。
- 确保所有必需字段都已填充,并且字段类型正确。例如,如果某字段要求为整数类型,我们需要确保输入的数据符合此要求。
-
ID校验:
- 根据元数据配置中的
idCheck属性,我们需要对每条记录进行ID校验。这可以通过查询数据库或调用其他服务来实现,以确保ID的唯一性和有效性。
- 根据元数据配置中的
数据写入过程
在完成数据转换后,我们需要将其写入目标平台。以下是具体步骤:
-
构建HTTP请求:
- 使用POST方法发送HTTP请求。
- 设置请求头,包括Content-Type等必要信息,通常为
application/json。 - 将转换后的JSON对象作为请求体发送。
-
处理响应:
- 检查响应状态码。如果返回200或201,表示写入成功;否则,需要根据错误信息进行调试和修正。
- 记录成功和失败的记录,以便后续审计和错误处理。
示例代码
以下是一个简单的Python示例代码,用于展示如何实现上述过程:
import requests
import json
def transform_data(raw_data):
# 假设raw_data是从AD流程中间表中提取的数据
transformed_data = {
"id": raw_data["id"],
"name": raw_data["name"],
# 添加其他必要的字段转换
}
return transformed_data
def write_to_target_platform(data):
url = "https://api.qingyiyun.com/write"
headers = {
"Content-Type": "application/json"
}
# 构建请求体
payload = json.dumps(data)
# 发送POST请求
response = requests.post(url, headers=headers, data=payload)
if response.status_code in [200, 201]:
print("Data written successfully")
else:
print(f"Failed to write data: {response.text}")
# 主程序
raw_data = {
"id": 123,
"name": "Test Data"
}
# 转换数据
transformed_data = transform_data(raw_data)
# 写入目标平台
write_to_target_platform(transformed_data)通过以上步骤和示例代码,我们可以高效地将已经集成并清洗过的数据转换为目标API接口所需的格式,并成功写入目标平台。这一过程不仅提高了数据处理效率,还确保了数据的一致性和准确性。
